Documentation pipeline
The talks about DevOps are still centered around continuous delivery and operating the production servers. Certainly this is important, but we already know how to do these things. What’s sorely missing is supporting the developers before they actually have something to deliver. If DevOps is really about working together and creating a culture, it should not be just about the servers and deployment scripts. It should be about working together on everything needed to create and deliver the software.
I have given a few talks about the documentation pipeline. If you are interested, my slides from Tampere Goes Agile 2015 -conference are available here: Beyond Continous Delivery: Documentation Pipeline. The following picture gives you the overall idea:
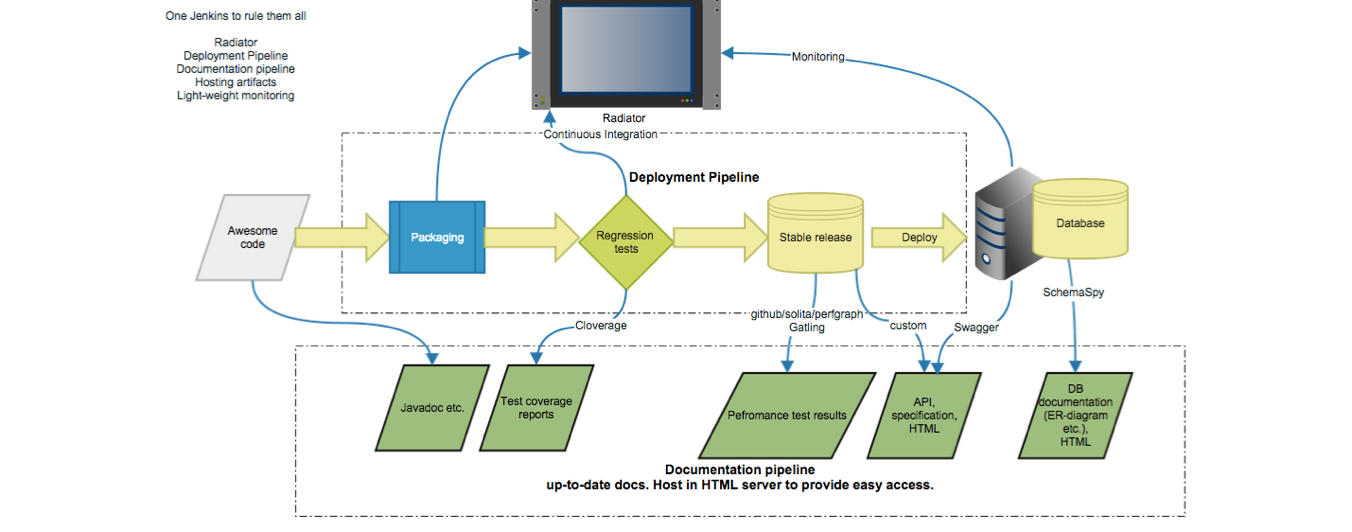
In this blog post we will focus on the database documentation and show how it can be automated and published.
Creating the database documentation
All relational databases have a meta model which is the internal model representing the tables, constraints and other elements which constitute the database schema. This meta model can be queried and examined directly with SQL or even programmatically through database drivers, such as JDBC. Hence, it is possible to create a tool which crawls the meta data and outputs the database schema in a suitable format. Several such tools exist, but in this example we are using SchemaSpy.
Interestingly, the meta model is not everything. A relational database can also contain comments, which can be used to document the meaning of various columns and tables and elements when the name is not sufficient. Comments can be defined with SQL, so you don’t need anything special to take advantage of this feature. Here’s a simple example for PostgreSQL:
COMMENT ON TABLE area IS 'Geographical area for something very interesting.'
Getting the metadata out
SchemaSpy can work with a single command, but we are using a simple script to run it. The script fixes the encoding to UTF-8 and a simplified version looks like this:
#!/bin/bash
set -eu
java -jar schemaSpy_5.0.0.jar -dp postgresql-9.3-1101-jdbc41.jar -t pgsql -host localhost -db awesome-db -u dbuser -p dbpass -s public -o schemadocs
cd schemadocs
# recursively go over the html files
find . -name "*.html" -type f |
(while read file; do
echo "found $file"
LC_CTYPE=C && cat $file | sed 's/<head>/<head><meta charset\=\"ISO-8859-1\" \/>/g' |
sed 's/ISO-8859-1/UTF-8/g' > charset_fixed.html
iconv -f ISO-8859-1 -t UTF-8 charset_fixed.html > $file
done);
The LC_CTYPE is mainly necessary for Mac OS, but you could do without it.
Running this script will write out a lot of documentation and also visual diagrams for the relationships between the tables if you have GraphViz installed on the machine.
Automating the generator with Travis CI
Running this on your own machine is impressive and useful as such, but we want a documentation pipeline. We want automated documentation to be available at all times and up-to-date without any manual steps. Originally we did this with Jenkins, but Travis CI is free for open source projects and it rocks. I don’t want to open our Jenkins to public, as I don’t trust the security on Jenkins.
Travis operates based on a descriptive configuration file. Our document generator is here:
sudo: required
language: clojure
addons:
postgresql: '9.3'
deploy:
provider: s3
access_key_id: "$ARTIFACTS_ID"
secret_access_key: "$ARTIFACTS_KEY"
bucket: opetushallitus-docs
local-dir: schemadocs
upload-dir: aitu
acl: public_read
skip_cleanup: true
region: eu-west-1
on:
repo: Opetushallitus/aitu
services:
- postgresql
before_install:
- "sudo apt-get install graphviz"
- cd ttk-db
before_script:
- psql --file=../env/db/dev.sql
script:
- lein run 'postgresql://ttk_adm:ttk-adm@127.0.0.1:5432/ttk' -u ttk_user --aituhaku-username
aituhaku_user --clear -t
- cd ../db-docs
- generate-schemadocs.sh
The script basically creates a empty database schema, then runs the Schemaspy script presented earlier and finally uploads everything to Amazon S3. To create the empty schema, we first create some database users with a SQL script and then execute automated schema migrations with Flyway. We wrote a simple Clojure wrapper for this, but you should use whatever you already have instead.
Travis makes it very easy to set up PostgreSQL and other required software packages needed. This is something you simply can’t do with Jenkins like that.
Uploading to S3
Getting the upload to work was a bit difficult at first. Obviously it’s very wrong to commit passwords and secret keys to source version control in plain text, so we refer to environment variables for AWS access. Environment variables are defined in Travis. A better way would be to use Travis encrypt mechanism, which hashes the secret key and only the hash is visible in the version control system. To understand the deploy part completely, read Travis guide for uploading to S3.
Creating a S3 bucket and setting up a static website in Amazon S3 is explained in Amazon S3 static hosting guide, which you should also read if you want to understand how S3 works. It is not overly difficult, but for debugging configuration issues I recommend the AWS command line client. You could, of course, upload the artifacts to somewhere else too. Amazon S3 is just what we are using for this project.
We need the Mighty DevOps heroes
In our example case, the documents are now available here: Aitu db docs. Amazon will take care of hosting, which costs some money, but the amount is negligible. Travis CI doesn’t cost anything as our project is open source. I would say this solution is much better than our own Jenkins, installing graphviz and all that, opening the firewalls and all that hassle. In a similar manner, one can automatically publish other documentation and artifacts with Travis CI in addition to database documentation. Here’s a more comprehensive example from another project: Osaan.fi Travis CI.
Automated documentation and automated publishing is the documentation pipeline. It’s not overly difficult, but certainly requires some “DevOps skills”, for the lack of a better term. This is one piece on our vision for the future of software development, and we hope that the DevOps movement extends their vision from delivery to development. We developers would really appreciate some help with this.