Just like software needs to be constantly refactored and its dependencies updated to keep it working and running, infrastructure needs some love from time to time as well. Our well known services kansalaisaloite.fi (github) and kuntalaisaloite.fi have been sitting on the same machines for a few years now and it was time to make some changes to keep everything under control, up to date and running. Apache HTTPD was switched to Nginx, Java 7 to Java 8, CentOS was upgraded to version 7 and so on. But it was also time to update the configuration and deployment processes.
Automate all the things!
We have always used Jenkins for automating the dev and test deployments, and our test coverage and QA are in a reasonable state. But in the old world we did not have the required control over the server configurations or production deployments. Even though deployments were mostly scripted, there were always some manual phases where you had to remember to execute all the deployment scripts on the right machines in the right order and in the right way.
I’m a huge fan of Continuous Delivery, QA and automation. I wrote my masters thesis (in Finnish) about Continuous Delivery and decided to apply some of the best practices of CD to these services as a part of this infrastructure update.
In Continuous Delivery, you should always keep your software deployable to production. Everything related to deployment should be automated and auditable: Server configurations, database migrations, deployments and of course unit and end-to-end tests.
At Solita, we mostly use Ansible for automated server configuration and application deployment, and the applications I work on are not an exception. The configurations for the 3 related applications running in 9 environments on 20 servers are now kept in one Git repository in a single branch. With Ansible, it’s easy to split the setup into tasks, roles and environments. You get the synergy of unified configuration for the common parts, while still being able to add configuration that’s specific to a particular application or environment.
Configuration pipeline
Although Jenkins itself can be messy and complex, its plugin ecosystem offers many reasonable tools for building deployment pipelines and archiving artifacts. All configuration changes should be deployed to dev and test before production, so it was obvious to make a pipeline for server configurations. I wanted to separate the server configuration pipeline from the deployment pipeline because they mostly change independently.
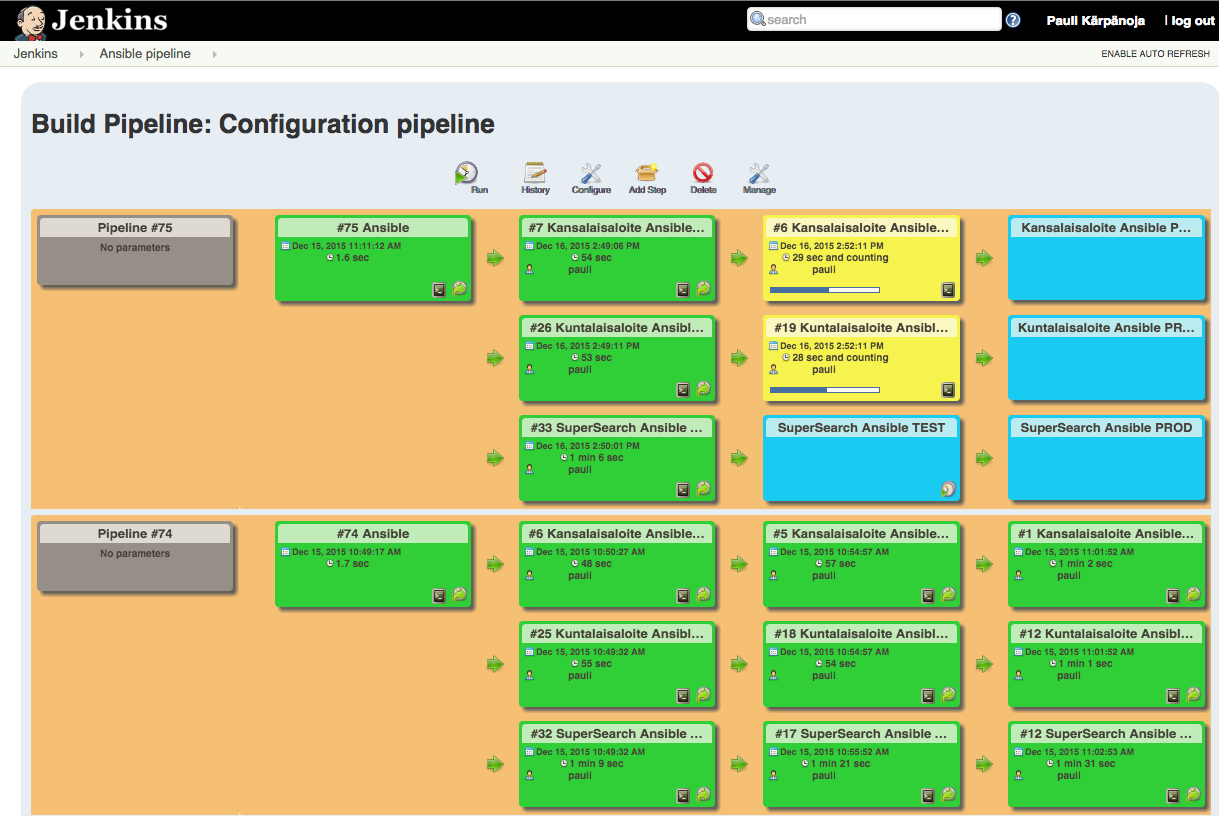
Every change to the configuration repository creates a new pipeline. With the Build Pipeline plugin in Jenkins, we can deploy the changes through the dev and test environments all the way into production with just a few simple mouse clicks. Each application has its own configuration pipeline. Every change leaves a trace in the VCS, and the deployments to each environment are automated and traceable with Jenkins.
Deployment-related changes to applications
Even though automated server configuration is a huge step when it comes to controlling the whole system, the applications and deployments needed some leveling up, too. The first thing was to throw away the separate Jetty server and WAR crap and build the application as a simple JAR file with an embedded Jetty server (commit). I did not have the time and interest for switching to Spring Boot so I ended up just including Jetty as a library. This change had a positive impact on the server startup time: It decreased from about a minute to a few seconds.
Another obvious change was to automate database migrations. I usually prefer to have a separate migration phase in the deployment process rather than letting the application migrate itself, but now I decided to go with the easy way: Include Flyway as a library, include the SQL increments in the package and make the application responsible for migrating the database on startup if necessary (commit).
Deployment pipeline
Now, lets talk about the deployment pipeline. Continuous Delivery relies on a deployment pipeline, in which every change in the VCS triggers the automated process that builds, tests and deploys the software. It’s very important that you build the binaries only once and deploy to production the same binaries that you have tested in the preceding phases and environments. In our solution, the CI job stores the JAR file, which is the Release Candidate, and deploys it to the dev environment automatically once it has passed the unit, integration, and end-to-end tests. After the deployment to dev, the same artifact can be promoted to the test environment and after that, into production. The deployment job runs an Ansible playbook that is also responsible for updating the application-specific settings (application.properties) during the deployment.
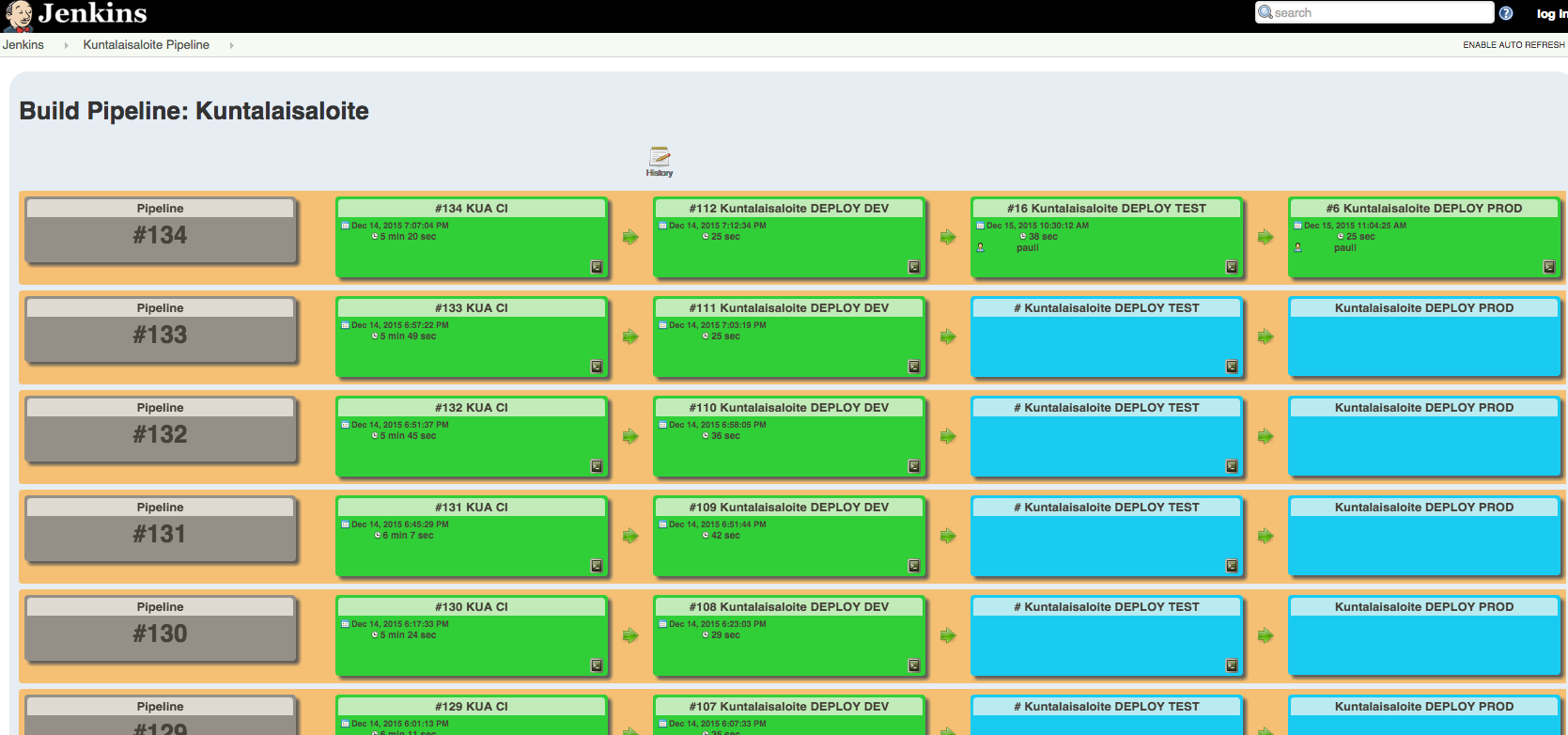
The deployment job also runs smoke tests against the application to verify that it started up normally. It also tails some of the application log during the server restart, so while the deployment is running, you can have a look at the log in Jenkins instead of having to go to the server yourself.
Now that all the environments share the same configuration process, deployment process and binaries, it’s very unlikely for the deployment to fail or any problems to occur in production. We always know when each version was installed in each environment, and reverting to an older version or server configuration is as easy as deploying it (as long as the database schema is kept backwards-compatible).
Stress-testing the new setup
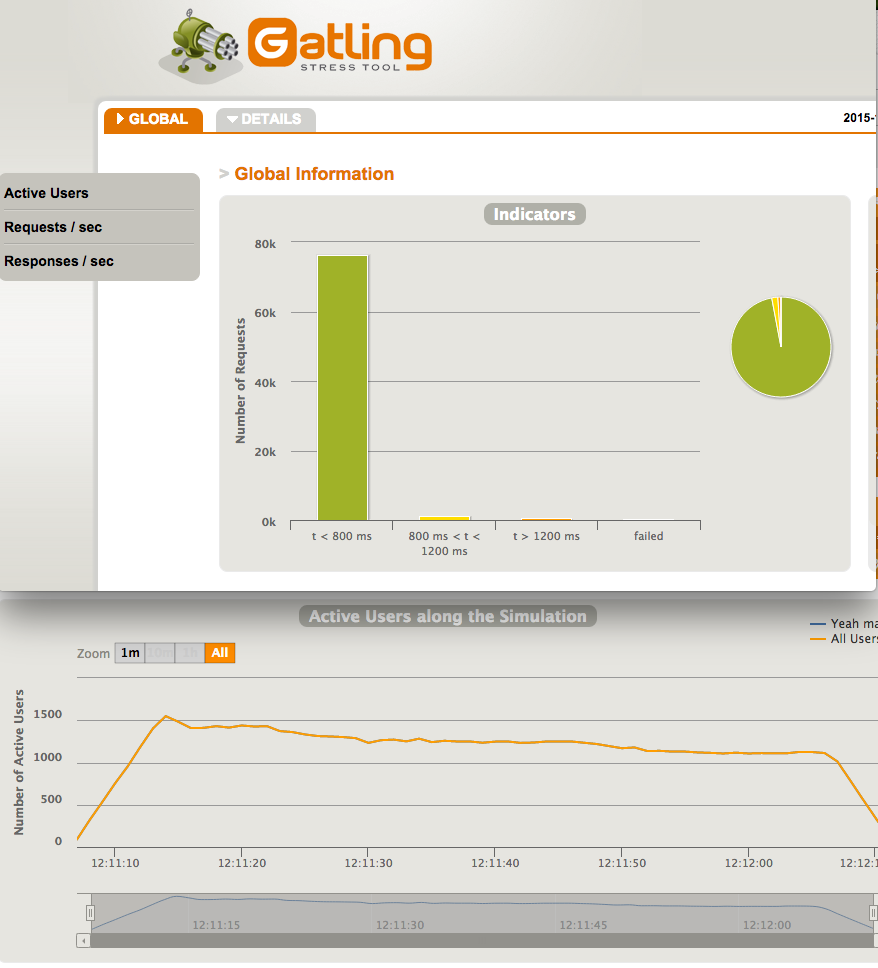
During this change I was also able to improve many other things, for example caching in Nginx. I wanted to run some performance tests to be sure we can still serve people with at least the same capability as before. We survived the massive Tahdon 2013 campaign pretty well and want to be prepared for other popular initiatives in the future. Gatling is a very simple and powerful tool for stress testing your application and it gives you many nice diagrams about the results.
Why all this?
The practices of Continuous Delivery make a massive improvement to the quality of the product, the stability of deployments and readiness to act when we need to make any changes to the application or the server configurations. Automation, reasonable testing and full control of the whole system are the key factors when it comes to quality and effectiveness.