The aim of this blog is to dip our tows into the world of edge computing. This is the first part of a blog series where I want to introduce the concept, talk about the benefits and go through some of the tools and technologies available. Having said that, I first want to make a small definition exercise.
Far edge, near edge, fog and mist, so many places where you can compute
As with any concept, definitions tend to get quite granular and nuanced as we dig deeper, and the concept itself matures. In this case, at least a couple terms have emerged. “The edge” refers to the networks edge devices, this could be an individual sensor, a device or a machine. This is sometimes referred to as far edge or mist computing. Processing of data that happens on dedicated compute resources is referenced as fog computing. In other words, fog computing introduces a new layer between the edge device and the cloud. Fog computing is also referred to as the near edge (as it is closest to the cloud). The definitions vary a bit by industry and by source. The important thing is that both aim for the same thing. They aim to move computing closer to the device layer, thus reducing latency, reliance on internet connectivity and bandwidth requirements. Also, some security concerns can be mitigated by keeping data local.
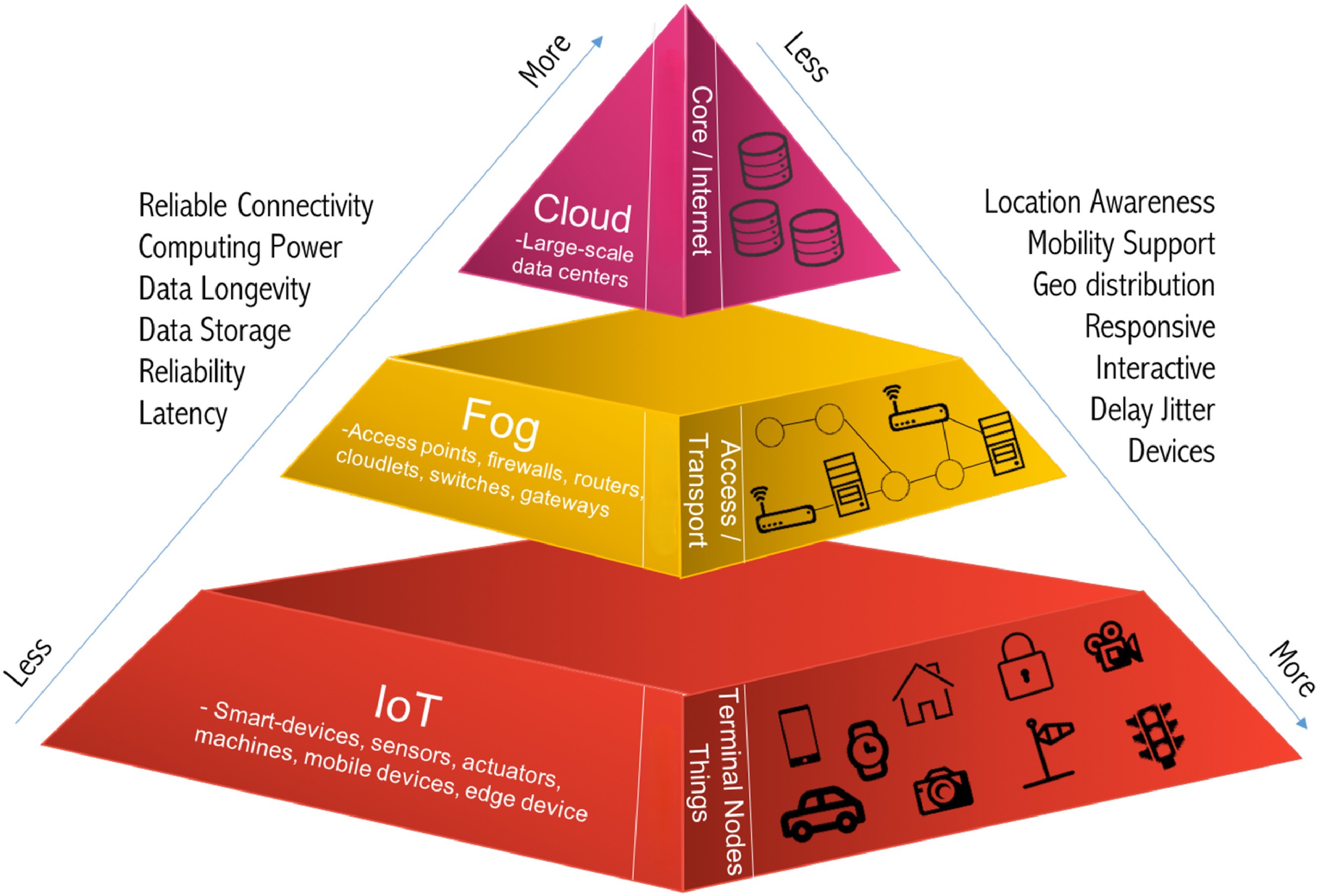 Edge computing layers, Modified from: https://www.sciencedirect.com/science/article/pii/S1383762118306349#fig0009
Edge computing layers, Modified from: https://www.sciencedirect.com/science/article/pii/S1383762118306349#fig0009
Having said all of that, for the sake of this blog, I don’t think we would benefit from this rather nuanced distinction, so I will stick to the simpler definition and refer to any computing done “below” the cloud as “the edge”. So, computing on a sensor, on a dedicated industrial computer, locally residing cluster or on mobile machinery all falls under the umbrella of “edge computing”.
How do we benefit from running workloads on the edge?
Running workloads closer to the data source will reduce the amount of data that needs to be sent to the cloud, as well as lower the latency for actions the data triggers when compared to cloud based systems. By moving some of the compute to the edge devices, the system also becomes distributed which in turn will make it more resilient. Physical proximity will also reduce the load on the network, as there is just less data to be transmitted.
An example use case to highlight these benefits could be a hypothetical traffic counting system. In this case, the actual visual data is not what we are after, we only care how many vehicles of certain type have gone past our checkpoint. So, what we can do, is to train a model in the cloud, deploy it to the edge and then relay only the analysis results to the cloud. This way most of the data will never leave the edge device, and if done correctly the system isn’t even reliant on a continuous internet connection.
There is also a security component in consolidating the communication between the edge and the cloud. Less connections means fewer attack vectors.
Another benefit I want to highlight is the ability to harmonize data on the edge. For example, in a factory setting we will have a myriad of devices that produce data in different forms, units and sampling rates. More often than not, the individual data streams need to be combined, they may need to be scaled, aggregated and or formatted. If we just collect data from devices and use that in whatever upstream cloud-based system, we have created a very tight dependency between the physical world and the cloud. A silly example would be an analogy temperature sensor. The output needs to be converted into a meaningful value, and this conversion will depend on the sensor. Change the sensor and the scaling logic might need to be changed. This should not affect any other components in the system than the component that reads the value.
Harmonizing egress data at the edge not only improves data quality but also mitigates this sort of issue as the edge provides an abstraction level that hides the implementation details of the physical system.
One last benefit that I want stress is connectivity. In the modern world we want to be able to manage our resources, may it be devices on the factory floor or machines out in the open from the cloud. Yes, we want to gather data, but usually we also want to do OTA (over-the-air) updates as well as monitoring, and sometimes we need to be able to set parameters or trigger some actions from the cloud. This sort of two-way communication requires some compute power at the device level and reliable, secure connection between the two components.
Ponsse wanted to leverage the above-mentioned benefits and partnered with us at Solita to achieve them. Ponsse has strived to be a truly data-driven company and as their machines operate all around the world, they needed a solution that can withstand times of offline use while providing data collection and transformation capabilities. Not only that but the system also increases the efficiency of their operations as it enables Ponsse to develop software components centrally and the machines themselves have the intelligence to download and install the updates when they have the possibility to do so. You can check the full story from here
Conclusion
In conclusion, edge computing offers transformative benefits for businesses by enabling near real-time data processing and enhancing operational efficiency through integration of the device-level with the cloud. This not only facilitates reliable data collection, and decision making but also allows for two-way communication and remote software updates, enhancing overall system functionality. These advantages optimize performance and open new opportunities for innovation as well as competitive advantage.