Me, myself & AI is a new artificial-intelligence-themed science exhibition at the Finnish science center Heureka. Solita was one of the partners for Heureka in conceiving, planning, and developing the exhibition during the past two years.
In this post, I’ll share some musings about implementing a piece of software that you can find in the exhibition.
Mission brief
I had the chance to take part in the exhibition development this spring as a mobile app developer. The idea was to build an iPad application in which an AI model would do object detection from camera images.
In the backstory, an absent-minded researcher built this app for herself. She’d use it to locate her important things before going on a trip. Exhibition visitors get to use the app and help the researcher to pack.
 R&D version of the exhibition item. Photo: Sampsa Piira / Heureka
R&D version of the exhibition item. Photo: Sampsa Piira / Heureka
In the concept phase, it was clear that we want to use a real-time object detection solution. With a rather tight time budget for development (roughly two weeks), we agreed to use a stock pre-trained model. Retraining with specific objects was an option to consider if necessary.
Model Selection
There are several object-detection models around for identifying items from images. These are often categorised into single-stage and two-stage models. The first fit better for real-time use cases, whereas the latter can support more object classes and have greater definition.
If you need to do it in real-time for several objects at the same time, there is not much competition for YOLO. This name comes from the original research paper: You Only Look Once - Unified, Real-Time Object Detection. The gist of this model is that it can locate objects and classify them in an image very fast in one single neural network pass. This makes it a good option for any application that requires object detection from the live video feed.
 YOLO model results in the application
YOLO model results in the application
Joseph Redmon published the original YOLO model paper in 2016. Since then, many individuals and organisations have worked hard to improve the model and make it easier to use. This work has made it possible for companies like Apple to bundle a version of the YOLO model into their own machine learning frameworks. The Core ML models published by Apple include three variants of YOLOv3. For this app, I used the smallest one to keep the app lightweight and fast.
I did some quick web research for alternatives to YOLOv3 and bumped into a company called Ultralytics. They have built a version of YOLO (YOLOv5) that has been designed for portability and ease of use in different programming environments. This model seemed to have very good detection rates in general, so I proposed to include it in the app as an alternative. Use of this GPL3 licensed model would dictate that the source code of the application has to be released with the same license. This was OK with Heureka, so I went on with integrating the new model with the application. For a detailed view of the model differences, you can refer to an article comparing YOLO v3, v4, and v5 for Autonomous Landing Spot Detection in Faulty UAVs. TLDR; the more recent model has generally higher mean average precision (mAP) while the older one has a higher framerate.
In the field tests done by me and the Heureka team each model yielded slightly better results over the other depending on the selected target objects, so both are available in the final app. The default configuration runs with YOLOv5.
Working with device orientations
When developing an app that uses live video capture and runs AI model predictions on it, you need to track things in three different orientations:
1. Raw orientation of the camera hardware
2. Orientation of the screen element that displays the image
3. The orientation of image array input to the AI model.
In my POC implementation, I took an approach that would allow the app to be used in any orientation. In retrospect, this was not the optimal choice. I spent several hours trying to figure out the poor prediction results before finding out that my model inputs were rotated 90 degrees left (the model would detect some objects but not all). It was an interesting challenge to get the predictions working from all angles, but in the end, we agreed to fix the device orientation to landscape. The final UI design was done for landscape layout, and when the camera is top left it is least likely that the user’s hand would obstruct the image.
Technical design
When developing apps for iOS today, the first choice is between SwiftUI or the more traditional UIKit approach. In this particular case, the decision was not hard. Dependencies to AVFoundation + Vision frameworks and heavy CALayer usage all called for UIKit.
Another important decision is whether to go for 3rd party frameworks or not. I’m a big fan of SnapKit framework, but for an app that is open source, I wanted to keep the dependencies minimal. In the end, I implemented the UI layouts with pure NSLayoutConstraint code. There is one extra dependency used for the award screen. The original plan was to use a GIF animation there, which we did, but I also added a little extra to task completion cheer with the SPConfetti animation framework. The dependency is added to the app through Swift Package Manager, so third-party dependency managers like CocoaPods/Carthage are not needed to build it.
The iOS platform frameworks used are CoreMotion for detecting when the device is idle and when it is taken into use again, AVFoundation for capturing the camera feed, Vision for image preprocessing and running inference with the model, and Combine for game events.
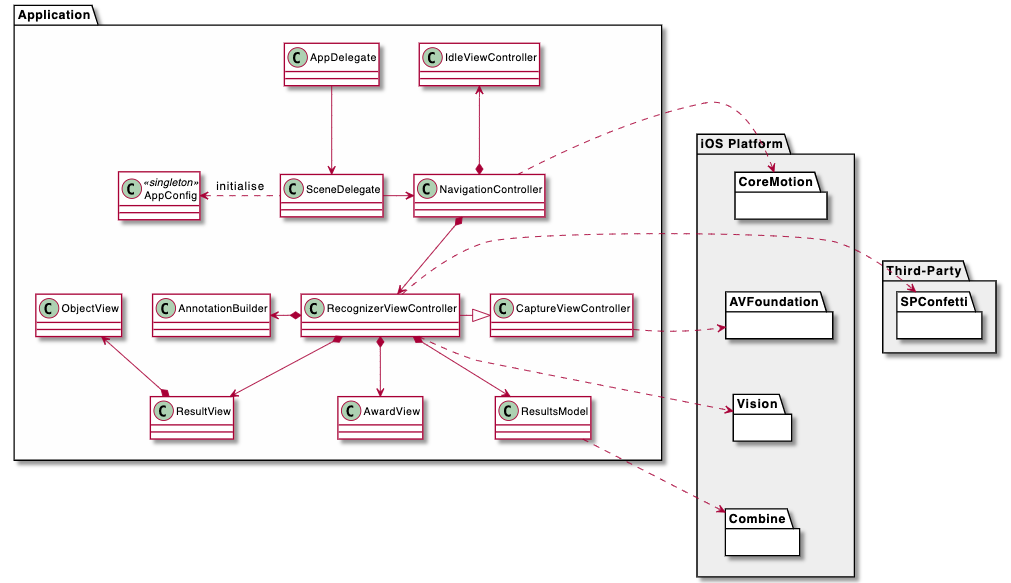
Application Class Diagram. Best experienced together with the code (see repository link in the closing chapter).
Finally, one of the project requirements was that application parameters should be configurable. The expectation was that the Heureka exhibition team can change certain application settings like timers, graphics, and languages in the app without the need to rebuild and review. For this, I designed a simple JSON configuration with the required fields.
I built the configuration parsing in a way that can cope safely with partial overrides and missing fields. Customised configuration and corresponding assets are uploaded through iTunes to the application folder. When the application starts, it will look for a custom configuration first, and run with that if one exists. If no customisations are available, the application will use the bundled configuration.
In the end, the configuration extended to cover pretty much all features of the app from UI to behavior. There is one exception to the run-time configurability though. An iOS app can load and use many assets at runtime, but the CoreML models are build-time resources. When it is time to update the AI models in the app, it will take a rebuild.
Gamification
A science center exhibition is designed to be an experience to remember. For our app, we also wanted to do more than a mere object detection demo. Something that would give a reason for the visitor to stick with it for a while, and give a nice feeling of accomplishment.
The solution to this was to add a goal to the app that visitors would figure out themselves with some minimal hints. The exhibition item consists of a table with many objects on it. Some of these objects were chosen to be targets for the game. All detected objects are annotated with a frame and object class text, and the target objects have a progress circle in the frame. To “collect” a target object, the visitor has to try to keep it steadily positioned on the screen until the progress circle fills up and gets checked. The target objects are also shown on the UI with icons that show the progress in tandem with the annotation. This implementation makes it easy to recognize the desired action when the first target object progress animation shows up.
 Testing the award screen. Photo: Roger Sandell / Heureka
Testing the award screen. Photo: Roger Sandell / Heureka
The YOLO models are customarily trained with the COCO dataset to detect 80 common objects in context. Our application displays a detection frame for all the 80 object classes, and five specific objects were chosen as target objects. The selection criteria was that items should support the backstory and have a steady detection rate on the exhibition floor. Also, the target object set is configurable in the app, as long as the desired objects are from the COCO dataset.
Some final takeaways
The power of modern mobile platforms is remarkable. You have enough computing power in your pocket to run an image recognition neural network, in real-time.
The AI/ML scene is delightfully sharing & caring. Data scientists publish their papers in open-access services, organisations and individuals put the science to practice and in many cases also release the source code for others to use and improve.
A pre-trained model can stretch to a variety of scenarios. You don’t always have to build and train your own models in order to create a meaningful and interesting app.
Where can I get it?
The app is in AppStore through Apple School Manager program under Heureka’s account. This means that you won’t find it in the public AppStore search. You can go visit the Me, myself & AI exhibition to check it out in the environment that it was designed for - or go to github.com/solita/heureka-objektintunnistin and build a version for yourself!