We all know the frustration when we just stop using a software feature because some action is taking too long. Quite often the reason for slowness can be pinpointed in the data retrieval from the underlying database. In this practical real-life example, we show some tips on how to analyze a PostgreSQL query plan to make related database queries much faster.
Data in Production Increases Over Time and Exposes a Slow Query
The code we use in our example belongs to an open-source software called Harja, a utility of the Finnish Transport Infrastructure Agency. One of the many things Harja can do, it provides some reports on bridge inspections: e.g. in what kind of shape a bridge is, are there any faults that need an urgent repair, and even links to photos that demonstrate the issues found. Some weeks back we received a bug report: the customer was not able to retrieve a report on the bridge inspections anymore. I knew it used to work for ages and nobody had touched the code for a long time – only the amount of data in the production database had increased. I looked at what was happening under the hood: the original SQL query from 2016 was very slow:
-- Translations for relations, as the code has been written in Finnish
-- silta = bridge, siltatarkastus = bridge inspection, siltatarkastuskohde = inspected property
-- liite = appendix, siltatarkastus_kohde_liite = link table between inspected properties and appendixes
SELECT
s.id,
siltanro,
siltanimi,
(SELECT tarkastusaika
FROM siltatarkastus st
WHERE st.silta = s.id
AND EXTRACT(YEAR FROM tarkastusaika) = :vuosi
AND st.poistettu = FALSE
ORDER BY tarkastusaika DESC
LIMIT 1),
(SELECT tarkastaja
FROM siltatarkastus st
WHERE st.silta = s.id
AND EXTRACT(YEAR FROM tarkastusaika) = :vuosi
AND st.poistettu = FALSE
ORDER BY tarkastusaika DESC
LIMIT 1),
(SELECT COUNT(*)
FROM siltatarkastuskohde
WHERE tulos && '{A}'
AND siltatarkastus = (SELECT id
FROM siltatarkastus st
WHERE st.silta = s.id
AND EXTRACT(YEAR FROM tarkastusaika) = :vuosi
AND st.poistettu = FALSE
ORDER BY tarkastusaika DESC
LIMIT 1)) AS "a",
(SELECT COUNT(*)
FROM siltatarkastuskohde
WHERE tulos && '{B}'
AND siltatarkastus = (SELECT id
FROM siltatarkastus st
WHERE st.silta = s.id
AND EXTRACT(YEAR FROM tarkastusaika) = :vuosi
AND st.poistettu = FALSE
ORDER BY tarkastusaika DESC
LIMIT 1)) AS "b",
(SELECT COUNT(*)
FROM siltatarkastuskohde
WHERE tulos && '{C}'
AND siltatarkastus = (SELECT id
FROM siltatarkastus st
WHERE st.silta = s.id
AND EXTRACT(YEAR FROM tarkastusaika) = :vuosi
AND st.poistettu = FALSE
ORDER BY tarkastusaika DESC
LIMIT 1)) AS "c",
(SELECT COUNT(*)
FROM siltatarkastuskohde
WHERE tulos && '{D}'
AND siltatarkastus = (SELECT id
FROM siltatarkastus st
WHERE st.silta = s.id
AND EXTRACT(YEAR FROM tarkastusaika) = :vuosi
AND st.poistettu = FALSE
ORDER BY tarkastusaika DESC
LIMIT 1)) AS "d",
l.id AS liite_id,
l.tyyppi AS liite_tyyppi,
l.koko AS liite_koko,
l.nimi AS liite_nimi
FROM silta s
-- problematic piece of the query starts --
LEFT JOIN liite l ON l.id IN (SELECT id
FROM
liite l
JOIN siltatarkastus_kohde_liite skl ON l.id = skl.liite
WHERE skl.siltatarkastus IN (SELECT id
FROM siltatarkastus st
WHERE st.silta = s.id
AND EXTRACT(YEAR FROM tarkastusaika) = :vuosi
AND st.poistettu = FALSE
AND urakka = :urakka
ORDER BY tarkastusaika DESC
LIMIT 1))
-- problematic piece of the query ends --
WHERE s.urakat @> ARRAY[:urakka] ::INT[]
ORDER BY siltanro;
The query above performs a LEFT JOIN of a bridge (silta) with its appendixes (liite), using an overly complex nested subquery. Subquery makes use of the bridge inspections (siltatarkastus) and a simple link table between inspections and appendixes (siltatarkastus_kohde_liite). First, it finds out the most recent inspection for a given bridge, then resolves the links to appendixes.
Analyzing the Problematic Query
Running the query against the production database took over 3 minutes to complete, so I wanted to find out more with Postgre’s EXPLAIN ANALYZE tool. EXPLAIN ANALYZE query plan reveals, the database planner does not seem to know how to work efficiently with our query but the database engine has to deal with massive amounts of unnecessary computation instead.
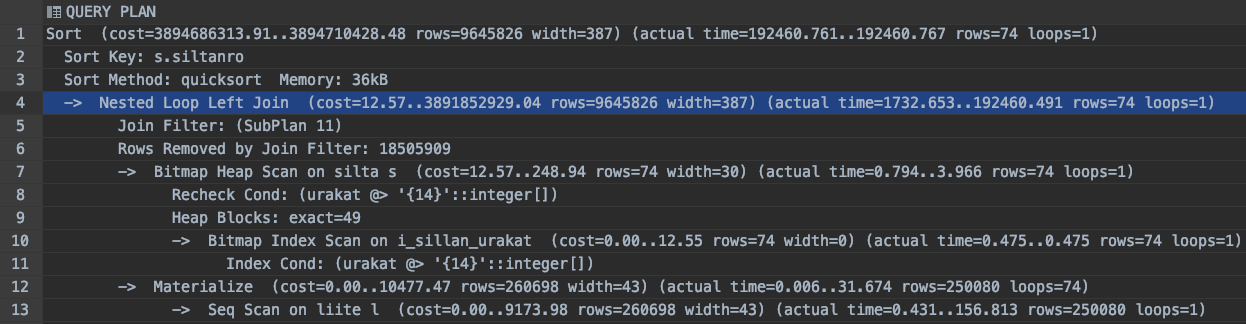 Original Query Plan Reveals a Big Execution Cost
Original Query Plan Reveals a Big Execution Cost
So what exactly can we see in this query plan? If you find raw query plans cryptic to read, there are also some graphical tools, such as pev by Alex Tatiyants that can help to visualize slow parts of queries. Usually, after some practice, it’s quite easy to spot the abnormalities in a textual query plan as well. For clarity and brevity, I have excluded all but the most interesting and problematic parts of the plans presented here. First, the database fetches all 250,080 rows in the appendix (liite) table with a sequential scan. Then we see that we have 74 bridges that belong to the project in question (urakka id = 14) that was given as a parameter into the query. This will give us a whopping 74 * 250,080 = 18,505,920 rows that will be looped through the NESTED LOOP LEFT JOIN condition, which is presented in SubPlan 11. This is for sure not what the original author of the code wanted to happen.
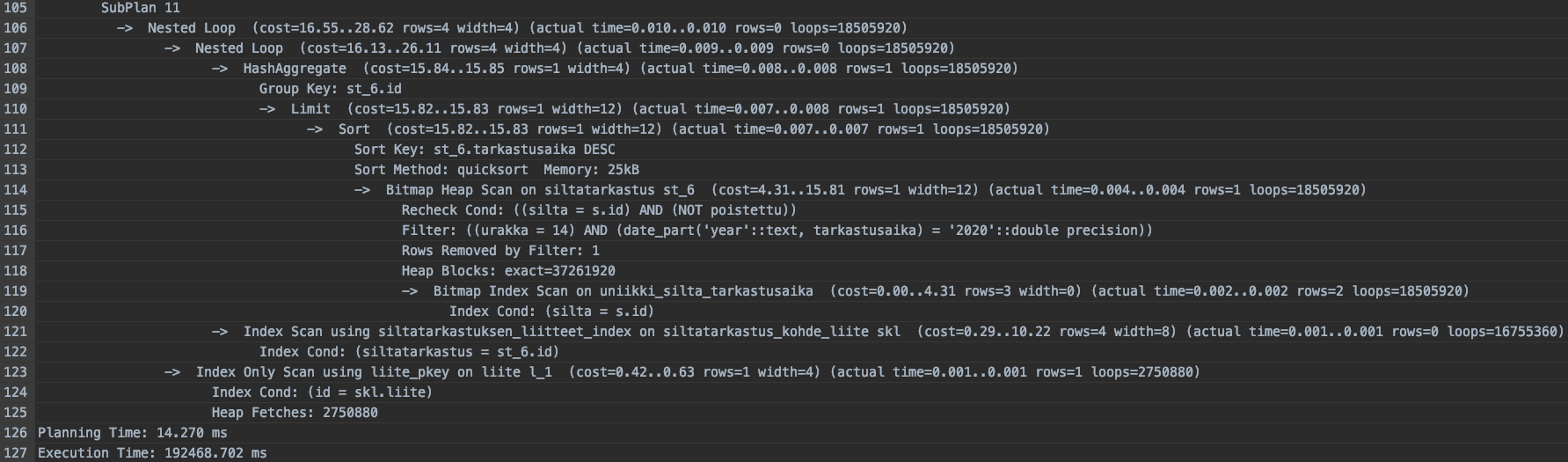 Query Plan of the SubPlan 11 Reveals Frequent Looping
Query Plan of the SubPlan 11 Reveals Frequent Looping
In SubPlan 11 details, we can see that the nested loop gets executed 18,505,920 times, with each iteration taking 0.01ms (see actual time=0.010..0.010, loops=18505920 in the plan), totaling 185,059ms which is more than 3 minutes. So most of the execution time is spent right here. Without knowing the ins and outs of the database planner, it’s hard to say why exactly this query produces such a slow algorithm, but most likely the way the subquery has been constructed does not leave the planner with any viable alternatives.
Improve and Reanalyze
Generally, a fast way to find out which part of the query code causes an issue is to simply remove parts of the code and run it again and clock it. Then remove another part, etc. as long as the slow part is found. With EXPLAIN ANALYZE though, we can skip the trial and error based hunting and get straight to the root cause. In the above example, we saw that our LEFT JOIN ended up doing a crazy amount of nested loops, resulting in a 3-minute query. A fast fix was to replace the subquery that was presented in SubPlan 11 with a more traditional LEFT JOIN.
-- The improved query has nested subquery replaced with two LEFT JOINs
SELECT ...
FROM silta s
LEFT JOIN siltatarkastus st ON st.id in (SELECT id
FROM siltatarkastus st
WHERE st.silta = s.id
AND EXTRACT(YEAR FROM tarkastusaika) = :vuosi
AND st.poistettu = FALSE
ORDER BY tarkastusaika DESC
LIMIT 1)
LEFT JOIN siltatarkastus_kohde_liite skl ON skl.siltatarkastus IN (st.id)
LEFT JOIN liite l ON skl.liite = l.id
WHERE s.urakat @> ARRAY[:urakka] ::INT[]
ORDER BY siltanro;
With a simple refactoring, we got rid of the most complex nested subquery, and have now two LEFT JOINs. Our execution time dropped from 3 minutes to 6 seconds! Let’s see how our plan looks like:
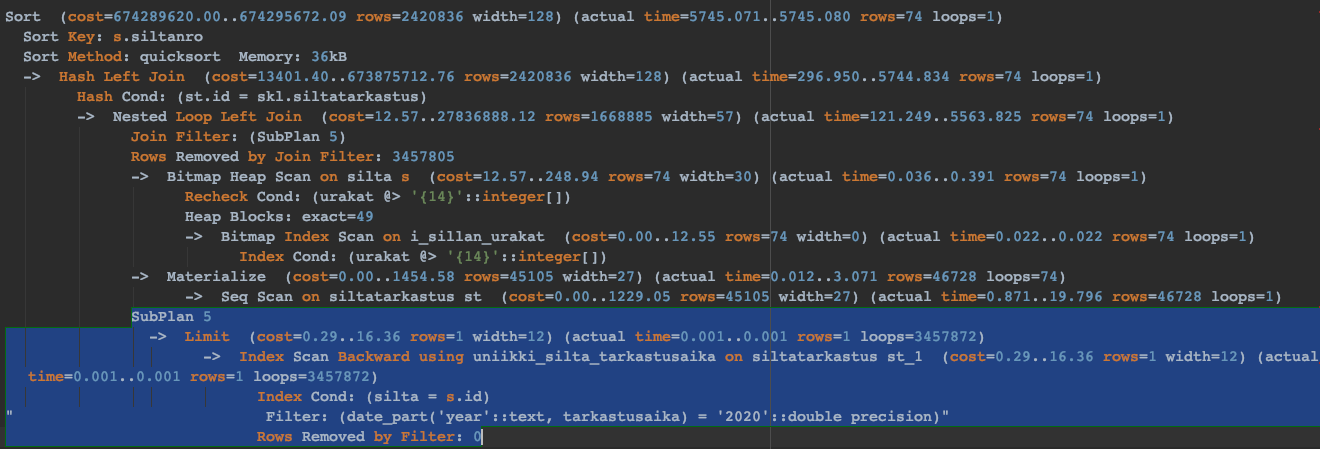 Improved Version Still Has Significant Execution Cost Because of the Looping
Improved Version Still Has Significant Execution Cost Because of the Looping
So even if we got to something much faster, we still can see row and loop counts in the plan that don’t make sense. We know there are only 50k bridges and 250k appendixes in the production database. However, the join filter in SubPlan5 is looped 3.4M times. The database engine will spend quite a long time aggregating the result set after performing the queries and joins. Based on the huge number in loop count, we can assume that the LEFT JOIN of siltatarkastus can still be optimized quite a bit.
The Power of a LATERAL Join
Next, we tried Postgre’s LATERAL JOIN to reduce the number of rows needed in result set aggregation and make the query even faster.
-- Final version with a LATERAL JOIN
SELECT
s.id,
s.siltanro,
s.siltanimi,
st.tarkastusaika,
st.tarkastaja,
(SELECT COUNT(*)
FROM siltatarkastuskohde
WHERE tulos && '{A}' AND siltatarkastus = st.id) AS "a",
(SELECT COUNT(*)
FROM siltatarkastuskohde
WHERE tulos && '{B}' AND siltatarkastus = st.id) AS "b",
(SELECT COUNT(*)
FROM siltatarkastuskohde
WHERE tulos && '{C}' AND siltatarkastus = st.id) AS "c",
(SELECT COUNT(*)
FROM siltatarkastuskohde
WHERE tulos && '{D}' AND siltatarkastus = st.id) AS "d",
l.id AS liite_id,
l.tyyppi AS liite_tyyppi,
l.koko AS liite_koko,
l.nimi AS liite_nimi
FROM silta s
LEFT JOIN LATERAL (SELECT id, tarkastusaika, tarkastaja
FROM siltatarkastus st
WHERE st.silta = s.id
AND EXTRACT(YEAR FROM tarkastusaika) = :vuosi
AND st.poistettu = FALSE
ORDER BY tarkastusaika DESC
LIMIT 1) st on TRUE
LEFT JOIN siltatarkastus_kohde_liite skl ON skl.siltatarkastus IN (st.id)
LEFT JOIN liite l ON skl.liite = l.id
WHERE s.urakat @> ARRAY[:urakka] ::INT[]
ORDER BY siltanro;
Lateral join allows us to cross-reference elements of the main query in the subquery, which is often very powerful. In our case, we can use the retrieved value of s.id (bridge id) returned in the from clause and use it in an SQL for-each kind of manner to retrieve columns of interest from bridge inspections (siltatarkastus). In our case, this seems to bring the query execution speed to a whole new level, from 6 seconds to 4 milliseconds! As we can see in the query plan after adding the LATERAL join, we can happily conclude that we finally got rid of the big amount of rows and loops in our plans that were signaling us something was not quite right.
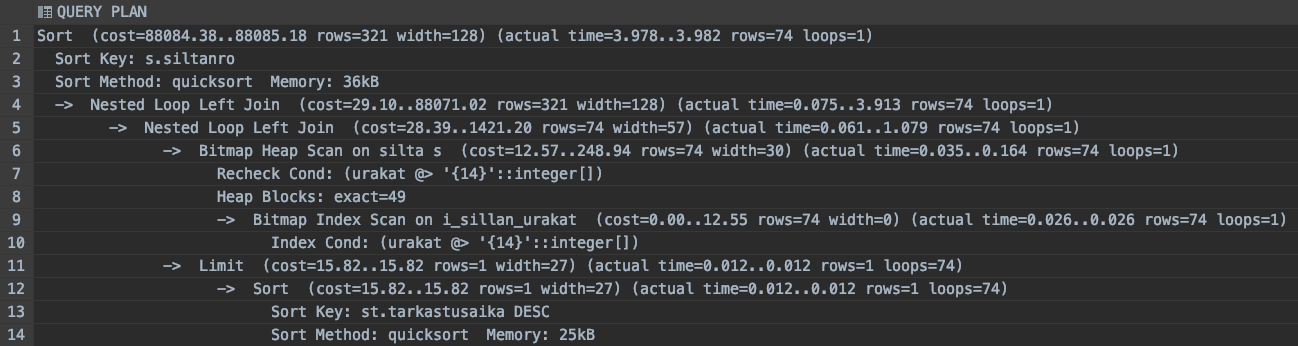 Query Plan of the Final Version
Query Plan of the Final Version
Problem Solved
Now the query seems to be doing pretty much what we wanted it to do in the first place, and hopefully nothing else. Our final query execution time of 4ms is just 0.002% of the original 192,460ms where we started from. Making this analysis and improvements to the code took less than one working day. Now we can happily respond to our end-user, and let him know that the bridge inspection report is again available, delivered and opened almost instantly after the mouse click.