EU General Data Protection Regulation is coming fast: There’s less than one year before transition period ends and regulation starts getting enforced. By now we’re all aware of the penalties: Up to 20 million euros, or up to 4% of annual global turnover, which can amount to much more. There are a lof of myths circulating, some panic, some doomsayers, and a lot of ignorance. I decided to write a piece on this, from my perspective, based on current understanding of how things are.
 Head to the sand
Head to the sand
I’ve seen two extreme approaches to GDPR. One typical claim is that the skies are falling, nothing can be done with data anymore, and nothing can be collected from users. The other extreme is saying: This does not apply to us, nothing will change. Both are wrong. Best protection is to get some more knowledge, and good place to start is to educate yourself. Read up on what you can. Some details will probably become more clear in years to come, but the big guidelines are already there. To keep this somewhat short, I will not be talking about organization level view, or existing software, but I will be concentrating on creating something new in year 2018.
GDPR For the impatient
Here is very short description of what GDPR is about. It is a new regulation, that is already in effect, but will be enforced starting next summer. As a regulation, it is to be followed exactly as it is, and it will replace old data protection directive from 1995. Core principles behind the regulation are empowering EU citizen’s whose data is collected, improving the security of processing of said data, and making the process more transparent. The fees and fines often mentioned are to enforce that it is taken seriously, and give a nice push to spend some money to fix any issues that arise. Afterall, to avoid 20 million fines, you can afford to spend a bit of money on security and privacy features and tools.
There’s also another interesting situation you might want to avoid. In case of a data breach, you need to notify DPO within 72 hours of detecting this breach, and then, possibly you might need to notify each registrar that the breach concerns. This is a PR nightmare, and can be a huge hit to business, especially if breached registry contains a lot of users, and/or you don’t have enough security forensics to limit what breach might have included.
GDPR is centered around concept of personal data, and comes with a lot of acronyms such as PII (Personally Identifiable Information), DPA (Data Protection Authority), DPO (Data Protection Officer), DPIA (Data Protection Impact Assessment), etc. I’m not going in-depth with those either, but to summarize, if you have data in your systems, in any form, and it contains data about people, and if an individual may be identified by combining that data, GDPR rules apply to it. To simplify, if I have a database of different apples, it is not interesting in sense of GDPR (It may be very interesting otherwise!), but if I collect customer data, it probably is GDPR regulated, even if there are no names or social security numbers. Individual may be identified in many suprising places, by combining information, for example address + first name, multiple geolocation points and timestamps, etc.
So myth number one is that nothing can be done with PII data anymore. This is simply not true. GDPR enforces transparency and person rights, proper documentation, and only collecting data that is relevant to the job you are doing. You need to have reason for collecting the data, and reason for storing it. But provided you do all this - it’s still okay to collect, even store and transport this data. You just have to do it right, with the new rules.
The other myth says that GDPR does not apply because I’m non-profit/small organization/this is not important part of my business. Bad news, it still applies. Of course collecting your own data and using it solely yourself does not trigger any sanctions or fees, but anytime you are collecting other peoples data that may identify them in certain circumstances, and do not apply the GDPR requirements, you are playing with fire.
Yeat another myth is that PII data is only something like social security numbers or payment information. PII data means any data that may be used to identify an individual, with reasonable work, even combining different sources. It also means any data directly attached to, or collected from said individual. So it’s much wider concept than just immediately and uniquely idenfifying bits of data.
There are already some interesting cases happening, even before the regulation is enforced. In Italy, February 2017, a fine of 5,9 million euros was imposed on a UK company for data privacy violations. In UK, a pub decided to rather delete its customer database alltogether than modernize it to follow the new regulations. So this is no time to play the ostridge, and push your head into sand, wait for the storm to pass. It does not really take much effort to make better software solutions in the future, and you will get added benefits. Furthermore, if you happen to find yourself in horrible data breach situation, and are facing potential fines, any correct actions you have done that you can show will be used to determine the amount of fines, so scale goes from 0 to 20 million or more, depending on company size. But I can guarantee you that you will be facing maximum fines, if you leak confidential customer data, in year 2018, and the only answer you can give to Data Protection Authority when they come with questions is: WHAT?
GDPR for software craftman
So, you are a software architect, or product owner responsible of producing a new solution to resolve a problem or improve business. While also old and existing software should definitely comply to data protection requirements, it would be utterly stupid to create new software without building the protection in. Most important points begin from non-technical solutions, and there’s the traditional point of diminishing returns. There is no such thing as guaranteed 100% secure or 100% GDPR compliant environment. This is a game of risk analysis.
So here’s a quick list of good steps to take for the impatient. This is by far not all inclusive, and a lot depends on the situation. But any steps you can take will make the software better and more compatible.
- Analyze risks
- Minimize collected data
- Justify data collection
- Document and explain collected data
- Protect the data
- Prepare for expanded user rights to data
Step 1 - analyze risks
Step 1 is pretty much a no-brainer, and is a part of any good security design as well. Think about your system, what are the biggest risks with it, what are the most probably risks to materialize. What is the worst thing that could happen? First of all, your countermeasures to mitigate risks should be always proportional. Secondly, it’s efficient to mitigate the biggest/most probable risks first, then continue to next one, until the risk level is something you can live with. Someone can claim to live with any risks, and hope there is never a data breach or violation, and none of the users will never exercise their rights, but I would not want to be the Data Protection Officer in such enterprise.
Step 2 - Minimize collected data
This is a new step. In the old days, there might have been a lot of data that was collected from user, based on a bit vague needs. “Let’s collect this just in case analysis could maybe possibly use this at some point later”. Simplest way to minimize the work of protecting the data, is to collect only what you minimally reasonably need to do this step in process. Nothing more.
You should also limit the data storage by time, meaning, define data retention policies. I’ve seen a lot of systems where data is never archived, and especially never purged. It is just collected. This means the amount of data you store just keeps on growing, and also risks keep on growing. Think about it. If you have a nasty case of data breach in your system, there’s a big difference between having to report and notify theft of 10 years of customer data, or half a month.
So define data life-cycle that makes sense for your application. No need to go overboard here, in many cases there are legal requirements to store data for some time. Even then, it might be wise to archive it in separate system, encrypted, offline, etc. But most important thing is to define, document, and explain the life-cycle of data.
Step 3 - Justify data collection
If you did step 2 right, this should be simple step. Your application has a reason for collecting person data. Good reason might be legal requirements. Another reason might be contract or customership. For some free-form data you might need to ask for consent. So there are meany good reasons for you to collect, process and store the data.
Do pay attention here, however. Common sense goes a long way. Customership does not give you free pass to collect any data, and store it eternally. Also old style of single-checkbox consent saying ‘I allow all’ does not work anymore, it’s specifically forbidden. If you go for consent, you should explain what is collected, why, how and how long it is stored, and offer as easy means to revoke the consent as you offer to give it.
Step 4 - Document and explain the collected data
Again, if you did steps 2 and 3 right, this should be an easy step. You should document what gets collected, why, and how it is stored, how it is moved. Important point is also to document the information flows, especially if they go over country borders, and even more so if they go over EU borders. So prepare to have some data diagrams, data flow diagrams, and documented details on how they are stored and how security is provided to guarantee confidentiality (enough in relation to risks).
GDPR has one specific requirement for being able to show the steps you have taken to enforce it, so documentation is very important part. It might be useful to also classify data in relation to GDPR, since you can find at least three levels of classification within (non-PII information, PII information, sensitive PII information), and this might effect how you protect different parts.
This documentation can and should be used as basis for any privacy policy documentation, that you produce and offer.
Step 5 - Protect the data
This is the part where traditional security mechanisms pretty much kick in. This is also are that has probably gotten even too much attention in GDPR. Let’s clarify this. You don’t need to buy intrusion countermeasure system or centralized logging solution or test data management tool to comply with GDPR. Also, if you buy one, it does not make you immune to any fees. It is just one detail in very large picture.
But any PII data you collect and move should be protected sufficiently. Traditional approach is to apply encryption, especially at rest, so if someone gets access to your database they cannot use the information. Anytime data moves you should consider encryption in transit, using secure protocols, and/or moving only encrypted data. There are also some new controls you can use, such as anonymizing or pseudonymizing data. Anonymizing means you remove any personally identifiable details, then rest of the data is free to use and move since it’s not PII data anymore. Just have to warn you - it might make data pretty useless, and also, succesful anonymization is suprisingly hard, and it is sometimes hard to judge what is sufficient. Pseudonymization means replacing identities with for example a token, so data seems anonymized, but link to actual identity still remains. It is not very effective control, and gives you GDPR benefits only is some rare cases.
You should also automatically include good audit trail logging, so if someone comes to ask you who changed this bit of data and when, you can answer that. Audit trail should also and especially cover read access for data. Funny thing is, that both access logs and audit logs may also be personally identifiable data, subject to protection. Also, they are worthless if anyone can log in to machine and manipulate them. So best practice here is to consider some kind of non-repudiative solution, such as pushing the logs to a write-only location such as encrypted S3 bucket with proper policies, or something similar.
Now, privacy rests on top of security. Without baseline security, there simply is no privacy. So to comply with GDPR privacy by default, you should first take care of your basic security. This should pretty much be a no brainer. The problem here is that many organizations may not have been very active at this front, they have been relying on luck. So there might be more to catch-up.
Some interesting areas to examine are:
- Physical security (Access to facilities and equipment)
- Social engineering
- Network security (Segmentation, firewalls, protocols)
- Password policies
- Admin accounts, user account policies, expiration, privileges
- Logging (Audit logging especially)
- Intrusion detection (Wide range of solutions, from cheap and easy to expensive)
- Configuration and change management
- Test data management
- Personal data in files
- Cloud services and mobile devices
- Data virtualization (as means of having centralized view of data usage)
Any amount of security you build in single application can be beaten with malicious ex employee with too much access. Or simply bored admin who noses around personal data. Or central printer where confidential documents sit for days. Or guy who walks in premises, social engineers an admin password, and turns off all logging and trails, then does what they want. Or infected USB stick. Well, you get the idea.
In ideal world you want to minimize access to just what is needed, even for admins, and to make sure everything leaves a trail, so we have forensics. These forensics can be monitored real-time to detect breaches faster, or used after a breach to find out what parts were compromised, to limit the potential damage. This does sound drastic but remember, anything listed here is not so important in sense of GDPR. But many of them still make sense in todays world, anyway. Just do your best, document current state, and do a roadmap of how you will reach the state you wish to be in.
The trick here is - this is not done when it’s done once. Everytime you make a change, things might change. Adding an innocent extra field, or just amassing more data might make identification easier. Making changes to configurations might open new holes (security misconfiguration is one of the top vulnerabilities these days). So security and privacy design is best seen as iterative process, not a thing you do once.
Also do remember, friends don’t let friends use production data for testing and training new systems. There are numerous ways to cope with that. Production data on USB stick for testing purposes is SO 1995.
Step 6 - Prepare for expanded user rights to data
This part has also got a lot of attention. Along with improved transparency, GDPR requires that you can answer registrar/data subject requests within reasonable timeframe. This reasonable timeframe is typically one month, but can be more.
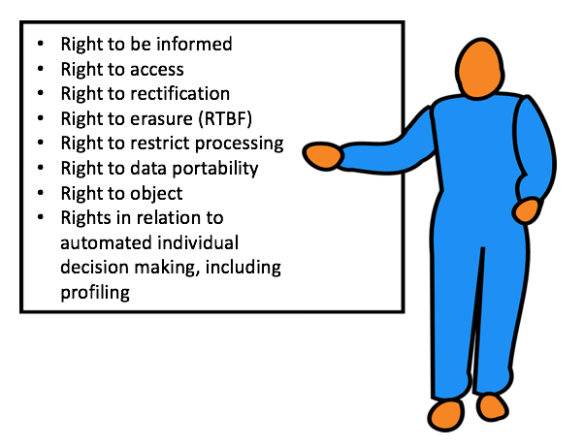 Data Subject Rights
Data Subject Rights
Many of these are common sense and have been already around. User has right to see what’s collected, how it is stored, and used, and for how long (transparency). User has right to check their information, and correct it (right to access and rectification), and user may restict or object to processing user data, of course within their legal rights. Some new things that have gotten a lot of attention are right to be forgotten and right to data portability. There is no requirement that all these should be digital self services, of course that would be convenient.
Data portability means capability of taking your personal data package out in some machine-readable format. Format is not important here, but of course if there exists any convenient industry-wide schemas, standardization is a good idea. Portability also includes possibility to transfer directly data to another service provider, if such exist. This is not a hard requirement, so minimum can be probably met by receiving a request, verifying it and identifying the data subject, then sending csv/json/xml package to them. Similarly, if user requests to erase all their data, you can provide technical solution, but many might be forced to use some kind of manual process.
Supporting these rights can be very easy in digital world. What is not so easy is identifying data subject. How do you identify and validate if your database has only first and last name? How do you validate if there’s only an email? All these scenarios can be definitely done, but make things a bit more complicated. If you already have established digital identity, where users can login, and it’s linked to your current data, yes this is the easiest scenario. Also note that validating data subjects request to exercise their rights is a very important part of this process. It makes no sense to erase all data if there is ongoing customership active, so this is probably protected by contract and common sense. On the other hand, if customership ends, would be good idea to consider automatic archival/erasure and notification. Data portability request is easier to validate in most cases, but some challenge areas include data that is interconnected with other persons personal data. In grey/challenge areas you can also reach out to local Data Protection Authority to ask for advice.
Conclusion
For me, GDPR is very interesting thing. Traditionally information security has not been a very sexy thing to implement, it’s been something often seen as afterthought, or even avoided alltogether. This thinking has created a lot of systems that are vulnerable, and in todays world, that’s a scary thing that simply cannot go on. There are countless examples of major data breaches, resulting in huge amount of personal information leaking and being misused. Finally, GDPR gives us incentive to put more emphasis on this sector, even spend some real money to do things right, and more secure. Not spending money here is becoming very expensive.
Furthermore, by making things more transparent, and empowering users to control what is done with their data, there will be more trust, and probably even more willing consent to do things with data we didn’t dream possible before. GDPR is not saying you cannot collect more data before - it just needs to be transparent, and justified, and secure. As long as people give their consent, you can collect and process even more data than before.
And finally, building support for user rights kind of leads to improved digital identity of registrars. Up until this day, many companies have databases full of information, that kind of identifies user, but is not really 100% accurate (identify based on email that was 8 years old, etc). Their customer databases may be filled with conflicting and outdated information. In other words, we are making bad decisions based on bad data. Doing the GDPR dance pretty much enforces you to improve the data quality and user identification process. By having powerful self services for registrars to verify, correct, and delete their data, and having defined life-cycles taking care of removing outdated data, things will get more accurate.
There’s a lot more to cover, but there’s also lot more good articles on different viewpoints to read. We will also be much wiser year from now, once GDPR starts getting enforced, and real life questions and calls need to be resolved. At this point in time, it’s enough to just make the best educated call on your approach, as it gives a great basis. Avoid panic, avoid temptation for ignorance. Enjoy the journey towards better security, privacy and transparency.