So, I went a week at the core of Silicon Valley, and listened to a lot of sessions, as well as free chatter on the hallways, and chat with people who have been working on projects all over the world. If you followed my earlier blog posts I’m sure you’ve already got your share of tech talk and immediate impressions. So this final post on the event is now more about my own opinions and views, summary of the event based on my experiences.

Oh, by the way, this is not the kind of executive summary for executives. This is still a developer blog. This is just more opinionated, higher level view of things.
Future of Java
Trust for the future is typically the core reason for this conference to exist. If there is no trust in future of Java, people slowly move on to using some other available platforms. This year was no exception to this. Before the conference, there was some grumblings about future of Java EE, and lack of information on the direction. Attending the sessions here, Java EE direction is now pretty clear, and makes sense. Only question is the pace, is it too slow? Is there enough resources to work on this? Planned pace is to release Java EE 8 next year, and Java EE 9 year after, offering more tools for cloud and microservices. But we’ll see how that goes. Lot of things are on very early idea-stage. On the other hand currently I don’t see anything in Java EE 8 and 9 that I would absolutely NEED right now, they are mostly conveniences to help me do more on the standard side and write a bit less code and perhaps use a bit less of extra libraries.
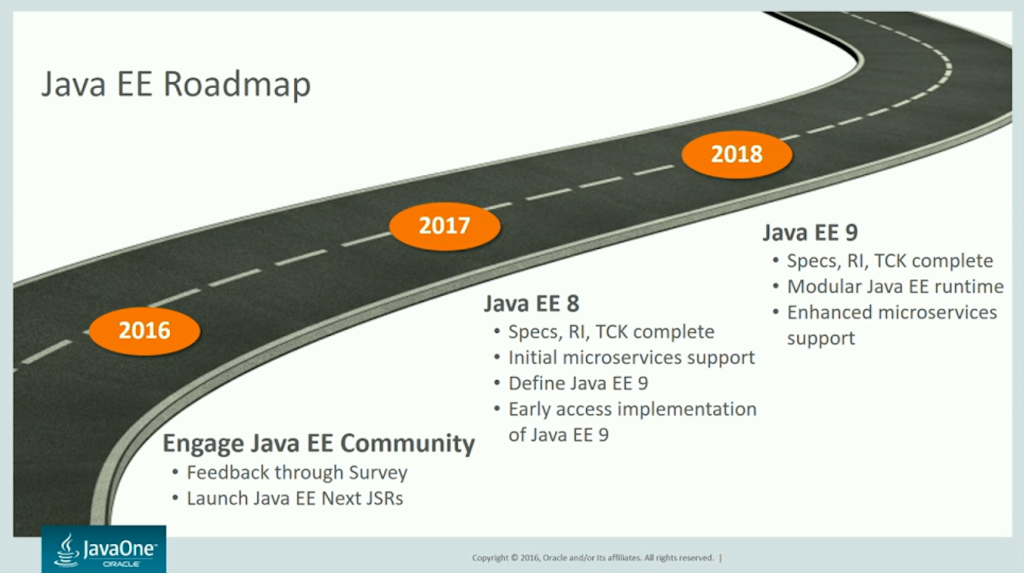
I was also here to learn much more on Java version 9. I had the idea that it would be released this year or early next year. But once more it’s delayed. However I wasn’t disappointed since it’s pretty solid already, and there was a lot of sessions and emphasis on it. Obviously main interest is the Jigsaw, but there’s a whole page of other changes coming with it. It is a major change, and it will break many libraries, frameworks, and applications, but then, many will also just immediately work, without changes. It is possible to grab Java 9 EA right now, and run your application on it. And actually, I met some guys who are running it already on production. I suppose living on the edge is where you feel most alive ;)
Anyone who’s not up to Java version 8, not using streams and lambdas all days, better pick up the pace now. Everything coming up will be heavily built on top of those features. They are not going away. It’s useless to hide.
Then there’s the MicroProfile rebellion. Not willing to wait for vague promises of Java EE 8 and 9 microservices support, a group of vendors made their move already, and released something called MicroProfile.io. Vendors include at this point IBM, RedHat, Tomitribe, Payara, and few others. MicroProfile is a subset of Java EE with a bit more rapid and free innovation. Core baseline would include at least JAX-RS + CDI + JSON-P, but plan is not to implement full Java EE 7, nor Web profile, but something more suitable for back-end microservices. Idea right now is faster innovation, for lighter containers. My thoughts? It’s great to have something now, not in two years, and innovate in more rapid pace. Perhaps there’s room to innovate more freely than on current full EE profile level.
Docker and Kubernetes
I’ve been Docker-curious a lot before, and I am using it extensively to ease up development. I’ve not been doing much with it in production environments, but that is going to change. I saw a lot of presentations on Docker, and chatted with a lot of people using it for their projects, and conclusion is, Docker is here to stay.

Java once provided awesome WORA-principle. Write the code once, then run it anywhere. This means portable binaries, which was a big thing back then. Docker brings next level to the mix. Portable binaries + environment. Furthermore, environment as code, as opposed to manually adjusting everything. Additional benefit being better use of resources. Once you start getting into microservices, or just managing multiple separate services, or wanting to manage clustered services, it makes more sense to use Docker than just shoot up full virtual machine each and every time. Docker is fast, lean, and supports very nicely current direction of Agile development and DevOps.
On performance side, Docker is pretty performant in production environments, most benchmarks tell a story of minor, few percent differences running software with Docker, or without Docker, so that extra layer might not cost so much. There’s also some tests done in AWS with thousands of Docker swarm nodes simultaneously, so it will scale up.

When you want to go deeper into Docker you pretty fast find some challenges, too. How to manage multiple nodes, how to monitor them efficiently? How to restart a node if a service fails? Depending on what you want to do there are multiple answers.
Docker-compose is a way to keep together multiple images and containers, for example database service, logic tier, load balancer. Currently it is most useful for development, but in few weeks a new version of Docker will be released, with improved support for packaging docker-compose containers for production, as a Stack. If you use docker-compose to compose a single application from containers, then next logical step is Docker Swarm, which allows you to manage multiples of containers, or probably stacks in future. Docker Swarm enables you to do things like load balancing, automated recovery, rolling updates, etc. And quite easily, I might add.
Then there’s Kubernetes. Piece of software from Google, to also help manage containers. Lots of containers. Google is spinning up and down billions of containers a week. That’s billions, not millions. So if you are using Kubernetes, you probably don’t need Docker compose, or Swarm. Kubernetes brings to play some more terminology, such as Node, and Pod. Pod is a flock of whales, such as Docker ;)
Kubernetes lets you do much of the same things than Docker built-in solutions, and it’s been tested on fields of fire - a lot. So there was also much hype about Kubernetes in the conference, and some great books coming up shortly. I did a lab where I combined Docker and Kubernetes with RedHat OpenShift. OpenShift adds some more convenience and monitoring on top of Kubernetes, it’s easy to visualize your topology and make configuration changes. So I was also impressed about that.
I’m not yet deep enough in these topics so I could make sense of overlapping/alternative models or best practices, but this is highly interesting area that I will keep investigating and experimenting more with, and what I’ve seen has encouraged me to implement some of these things more rapidly, when there is an opportunity. It’s about more configurations as code, and it’s about more efficient usage of existing resources.
Microservices
So, once more into microservices topics. I’m all hyped up about them, and we are already using them successfully a lot. That being said, it’s pretty obvious that there’s a hype bubble going on about them, much similar to what happened with SOA. Not all monoliths are evil, and many of the microservices projects will generate a lot of ugly mess for years to come.

So first figure out if you’re in a place where microservices will bring you some happiness. If you decide to go for it, prepare for some challenges. Here’s a checklist to see if you are ready for them:
- CI and CD are how you already do things, you enjoy them and are successful with them
- DevOps is what you do - whatever you mean by that. You have control of your environments, and have monitoring, tracing, and all your environments are pretty much identical. And you have capability of duplicating them, destroying them, and bringing them back. However you do that.
- You understand the challenges and responsibilities of running 100 services - because you will pretty fast have at least dozens of them once you get started.
- You are no stranger to Docker, in production. To improve the points mentioned above, you need to be friends with containers. Whether you just deal with simple containers and Docker compose, Docker Swarm, or Kubernetes, it simply makes sense to use containers instead of virtual machines. Unless you have modest needs but crazy budget, in which case do what you wish :)
- You understand that microservices are not about re-use, they are about modularity (Difference to SOA thinking)
Got this far? Cool. All projects are not similar Twitter and Netflix, so you can do some things with a bit more carefree approach. But remember that the amount of microservices you end up having will be the multiplier for failures you will be experiencing. There are a lot of excellent solutions and patterns for this already, but simply slapping Hystrix in the mix will not work, you need to design for failures from the very beginning (Failure-first development :) Trick is to aim for controlled failures, where optimally API users will not even notice short failures, but where your ops team has fast capabilities to detect, locate, and fix. The worst case scenario without this design model would be multiple places where things can break, and any of them breaking causing a snowball/avalanche effect, taking any dependent apps down with it.
One good hint that I got from the conference was to very early separate timeout-related errors from actual unexpected errors, to help you diagnose and trace faster.
Reactive programming
It also seem every other presentation at JavaOne had some reactive programming twist to it. When you start going Microservices route, you don’t absolutely need to do it asynchronously, or apply reactive programming, but they will definitely bring you some benefits, again for more efficient use of resources, and better support for handling network failures.
One ready-to-go framework for reactive Java was Vert.x. I didn’t happen to attend sessions on that topic, but saw it demonstrated on many other sessions. Furthermore, there are good instructions and tutorials on framework web pages, and after JavaOne, there are some good labs and presentations too. Vert.x. bring simple reactive programming model for both client- and server-side. What little I had time to play with it, it seems pretty promising. I’m more used to existing Akka programming models, so I’m curious to go a bit deeper on how they compare. Cannot give you much insights there yet. Then there’s third option, Reakt, but I didn’t see as much hype about that as there was for Vert.x. No personal experience there so again, would need to do some comparisons across all of these.
Of course, reactive rage is going to be one of the core themes of upcoming Java EE 8 and 9 releases, too. At moment, however, it seems quite unsure of what that means, and you can say it’s a volatile, moving target right now. It also bring opportunity to participate with JCP work, and effect it with your opinions. However, reactive programming models in Java EE will probably include using the Java EE server as basis, so until they make it much more modular, it’s a more heavyweight solution than Vert.x. or Akka.
Of course from my viewpoint, reactive server-side is optional choice. I haven’t yet found many cases where I would really absolutely need one, but in modern microservices world some scenarios are emerging more and more often where that might be the case.
IoT
It’s not big surprise that cloud and IoT were topics of many sessions, and many demonstrations here. They have been for many years already. There were countless Raspberry Pis controlling robots, 3d printers, coffee machines, reading your gestures and moods using Watson cloud power, and collecting information from visitors (voting booths were done by a raspberry pi unit each)

I also attended a workshop with an Arduino chip talking to raspberry Pi talking to Oracle cloud. Trick here is that Arduino is even cheaper platform than the Pi, and if you have just some wireless connectivity, and possibility to hook on some sensors or radiators, it’s enough. MQTT protocol seems to be the choice of the day for connecting the world around us to the cloud. Of course security requires encryption at least, and that’s where the Pi stepped in: Arduino chip doesn’t have much processing power, whereas Raspberry Pi is essentially a small computer, as powerful as many virtual servers used today.
My reading is that IoT has become less exciting, less hype-y, and more mature, part of our everyday life. We have moved on from the stage of how to get connected to optimization, how to connect efficiently, how to do it cheap, so you can have hundreds of thousands of IoT units in the field. How to be stingy with the drain on batteries. I also saw some pretty powerful demonstrations on how to analyze an image, for QR code, or for emotional state, using cloud services.

So we know we can do it. Whatever it is. Now we enter the phase where we think more what we want to do with it.
Miscellaneous notes
- IBM is open sourcing it’s JDK 9
- Netbeans is now Apache Netbeans
- Corba module will be deprecated in Java 9 :)
- Java EE 8 will also contain key/value document DB API - that is not based on JPA!

Well, next year JavaOne will be back at October 1st to 5th, so we’ll see if Java 9 and Java EE 8 are done by then or still a year away ;)
Links and resources
Microprofile.io http://microprofile.io/
Vert.x reactive toolkit http://vertx.io/
Akka actor framework http://akka.io/
Docker https://www.docker.com/
Kubernetes http://kubernetes.io/
JavaOne sessions list at Reddit https://www.reddit.com/r/javaone
High speed reactive Microservices https://github.com/advantageous/j1-talks-2016/wiki/JavaOne-High-Speed-Reactive-Microservices-2016
JavaOne 2016 session recordings https://www.youtube.com/playlist?list=PLPIzp-E1msrYicmovyeuOABO4HxVPlhEA
SonicPi: Programming as Performance https://www.youtube.com/watch?v=J8Dd2SIAWJw