The software project concerned started in the beginning of autumn 2010. I had the honor to work in the project as a full stack developer from its beginning to June 2014 when my maternity leave began. The project’s goal was to renew a 30 years old, technically outdated registry and everything attached to it, such as the user inteface and all the integrations. After three years of hard work the application was taken into use in production. The project is still alive and kicking, in maintenance mode with some feature developement.
The Application
The application is written in Java. The actual user interface of the registry is developed as a web application using Apache Wicket, which is an Java web application framework. The data is stored in Oracle database and queried with direct SQL-queries, without any intermediate layer such as Hibernate. There are also numerous integrations bubbling under, powered by Mule.
The views in the user interface are designed in such a way that the user can see the main item and all the sub-items related at the same time. The main item could have several sub-items listed in a table-like manner. The main item has certain managing tools and actions and, of course, all the sub-items have a bunch of tools and actions too. Most of the tools are implemented as icons with actions attached. The state and visibility of the tools depend about the status of the main item, but also from the context. Is this the main item which created the sub-item, the main item which edited them or a main item having nothing to do with the others? In addition to, some notification icons need to be shown in certain situations. However, after all we had a number of different icons which should be visible if and only if the sunspots were in the right position.
At least for me, the variety of showing data depending on the context was also a burden. The functionality behind hiding and showing the icons respectively was very easy to break by sincere mistake when implementing some new feature or tweaking an existing one. Also, the number of different permutations were so vast that it was nearly impossible to make full regression testing just by clicking the web site manually. I feel this was the main reason we started to write automated end-to-end-tests in quite an early phase of the project.

The First Try with Wicket Unit Tests
The first automated e2e-tests were written using Wicket Unit Tests. The unit tests utilized WicketTester, which runs the application without the need to actually run a web server. You can validate the web page opening, click some buttons, fill fields, run the business logic and validate the web page after. The Wicket tests are pretty quick to run and fairly simple to write. But there are also disadvantages, the tests are not actually testing the full pipe, because the lack of web server and browser. Also, the Wicket page tester does not render the page, meaning that in a case of exception or assertion error, the actual web page cannot be seen. It is like trying to find a needle in a dark room. Furthermore, the actual page structure can be seen only in debug output, i.e. finding the components to assert is not always easy.
However, despite the impediments, these tests were found very helpful. The objective was reached, the tests made the user interface more robust. The tests verifiyed the icons were visible and clickable in the specified situations, and even more, if you broke functionality by accident it was exposed by a test.
The New Era with JBehave and Selenium
After a while, we got a testing specialist in our project, and a new era began. He started to build real automated e2e-tests with JBehave and Selenium. JBehave enables writing the tests as stories in text files. Each story file has a matching Java class implementing the steps described in the story. The steps and the actual test code are mapped together with annotations. The web page actions, button clicks, element searches and so on are written in separate bridge classes (e.g. MainItemPageBridge.java). The tests are run with the help of Selenium Web Driver, which links the actual web page and the test code together.
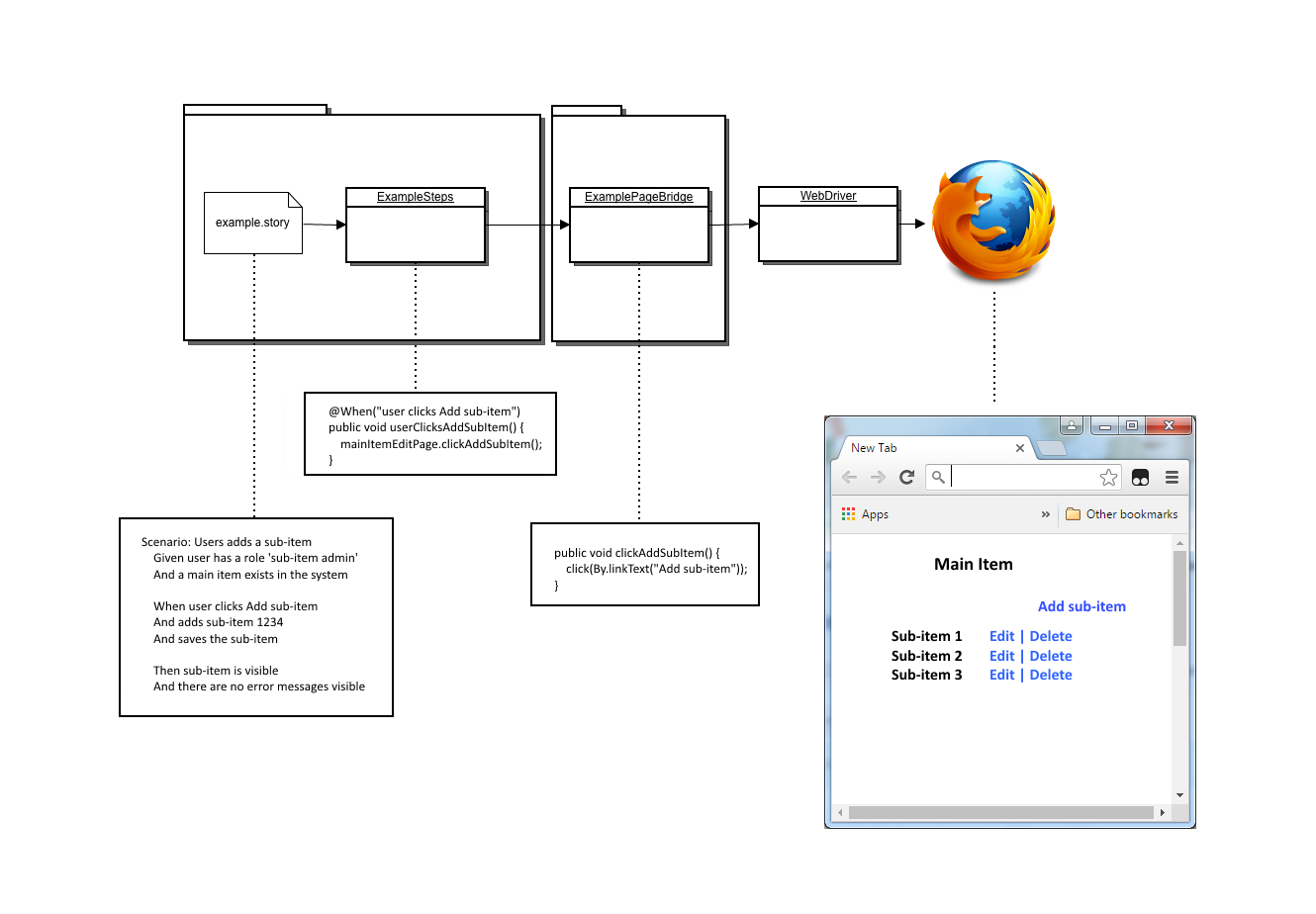
At first, there was a huge gap between code implemented and code tested with JBehave tests. There were a couple of developers just writing tests for the already implemented features. However, soon it was clear, that despite the effort the gap would remain due to ongoing feature development. Hence, everyone in the project should learn writing the new type of tests for the features implemented. In my opinion, in the beginning it was slow and not very easy but step by step it became a natural way to write tests. Of course, the test framework was developed side by side with the tests, because we wrote a lot of common utility methods and tools.
The JBehave tests were slower to run than Wicket tests, because opening the browser took time. When the number of JBehave tests grew, we realized that running all the e2e tests on our own workstations was too time consuming. Hudson, which is our CI platform, was configured to run all the tests after a bunch of commits. This way we could run only the relevant tests on our own workstations and the full regression tests were run by Hudson. Hudson was also configured to save the print screen images if JBehave tests failed. The images are a huge help when trying to figure out why the test failed. The inspected element might be missing or maybe the test is not clicking the right element at all. The JBehave tests are also worthwhile when debugging the application. The scenario can be set up programmatically before the browser is started. After that, you can run the test step by step watching similarly the actual action on the web page.
To some extent test stories can be used in communication between customers and developers or as a basis of user manual. However, soon we found out that keeping the stories in such a documentative way, is hard and on top of that not really beneficial. Also, the lack of IDE support for writing story files and matching the steps in the stories and in the test code is a little frustrating. It would be nice to find mismatches because of typos before you run the test, or navigate directly from a story step to the code implementing the step. One can say, that a number of text searches were done to avoid the problem. Furthermore, the finding right web elements to assert is not effortless with xpath either.
Our end users were using Internet Explorer, but however, we could not get the tests robust enough using IE. The tests were failing quite randomly time after time. Hence, we used Firefox to run the e2e test. Even though the tests used wrong browser the benefit was obvious. Furthermore, we had problems updating the Firefox version but after we freezed the Firefox in the certain version and disabled the auto updates, everything was fine.
However, despite minor disadvantages I find the automated e2e tests really valuable. It is not enough to test that the data is queried correctly from the database. In a full stack software there are still numerous layers where something can go wrong. For example, some sloppy CSS notation can hide an otherwise perfectly functioning element. The e2e tests bring some reliability in programming. Of course, we have a loads of unit tests also in lower levels testing data access objects, services, business logic, integrations and so on. The e2e tests are too heavy and too far away from the actual problem if you are trying to debug a database operation or some business logic functionality.
The Value Obtained
The comprehensive regression test suite including both the e2e tests and the unit tests gives depelopes courage to refactor the code base more freely. After all, all development is easier, because the mistakes are quite likely to expose on some layer of tests. This is extremely valuable when new developers are introduced to the project. In a long-lasting project you cannot avoid coders changing, some are coming and some are going. Of course, the rookies cannot have the all functionality and information in their heads as the experienced, tough warriors. Hence, the automated tests lower the step when entering to a new project, and as I think, ease the mental burden of both newcomers and old-timers. I would say, that extensive testing also enables healthy and needed rotation of developers between projects. The extensive automated testing is crucial also in the maintenance phase of project. The changes to code base might be done less frequently and the developers making the changes may not be the original personnel any more.
The tests written act also as documentation, even if they are not written in a documentative manner. If a feature is implemented in one way and there is also a test written in such way, there might be a reason to keep the feature as it is. At least there should not be a reason to change the behaviour without a consultation with the developer.
After all, it is always better to find the bugs before they are installed to the customer’s environment. If installing an acute bug fix patch can be avoided, it is always a good thing (yes, our deployment process was not very agile). The earlier you find the bugs, the less the fixing costs, and the more high-class and professional the project appears to the customer. Of course, we did not totally avoid bugs and bug fix patches in the software project concerned, but I think, without this amount of testing we would had them even more.