Elastic{ON}16 was held in San Francisco 17-19.2. 2016. As the only Elasticsearch partner in Finland, Solita naturally participated the event. For Solita Elastic{ON}16 started already on the 16th day because the flight was full of ElasticSearch core developers and we had plenty of time to talk with them about ElasticSearch and what is going on with the stack.
What is Elasticsearch and what are the core business cases for it
Elasticsearch is a scalable search engine for full-text search. It is build on top of Lucene and it works through REST API. Elasticsearch has three following core business use cases.
- Unstructured search
- Log management
- Analysis
In Elastic stack there are now multiple products that help in achieving all above.
- Elasticsearch: The main search engine
- Kibana: Visualization tool for data analysis
- Logstash: ETL tool for sending data to Elasticsearch
- Beats: Lightweight datashipper for Elasticsearch
- X-pack: Plugins for Kibana and Elasticsearch that are available for subcscribed companies
- Cloud: SaaS version of Elastic stack
Versioning
Versioning is unified. LogStash, ElasticSearch, Beats and Kibana will all get new major version 5. All the products will have common release schedule in the future which makes it easier to be sure about the compatibility of different modules of same stack. Elasticsearch, Kibana, Logstash and Beats got also new unified logos.

Stay tuned since Elasticsearch-5.0.0-alpha1 will be available soon!
New features in Elasticsearch
There were a lot of stuff going on and we have surely missed something but here are some of key topics that we want to bring up.
Security
Java Security Manager has been integrated into Elasticsearch. If additional security is needed then Shield add on within x-pack can help in securing the elasticsearch. Shield provides authentication, authorization and field level security for your installation.
Profiling
Profiling API has been added into product that makes it easier to understand what takes time within the search engine in your possible slow queries.
Scripting
Scripting support is about to come back with new scripting engine that should be much faster and also safe.
Data structures
String is divided into two separate field types. “text” is used for full text field that is analyzed and used in relevance calculations where “keyword” is used for concrete string values where we normally do not want to do any analyzes.
Search
Deep paging support with “search_after” functionality with linear performance. In previous Elasticsearch versions deep paginating might have been really expensive becauce the engine needed to run same query multiple times.
Java HTTP Client
Java client has been now decoupled to server and client. This makes it nicer to use the client since it does not have anymore so many dependencies it used to have.
BM25
Before Elasticsearch 5 the relevancy scoring system has been TF/IDF which means term frequency per inverted term frequency. Term frequency basicly means that the more searched term is found from document the better. Inverse document frequency in the other hand means that common words should be less important (imagine having term “the” in your search keywords). Shorter document with same term frequency was better than longer document. If there were multiple search terms then the documents that has them all are rewarded for that.
This is about to change now to BM25 which is inspired by probabilistic ranking. The reason for the change is that even TF/IDF has been succesfull it has been more or less adhoc approach that suits most cases well. Literature, challenges, users and lucene developer suggests that BM25 could do better than TF/IDF. BM25 also gives us possibility to adjust more the behavior of ranking by tweeking parameters. But it is a harder one to understand. Here it is:
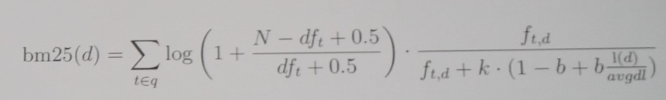
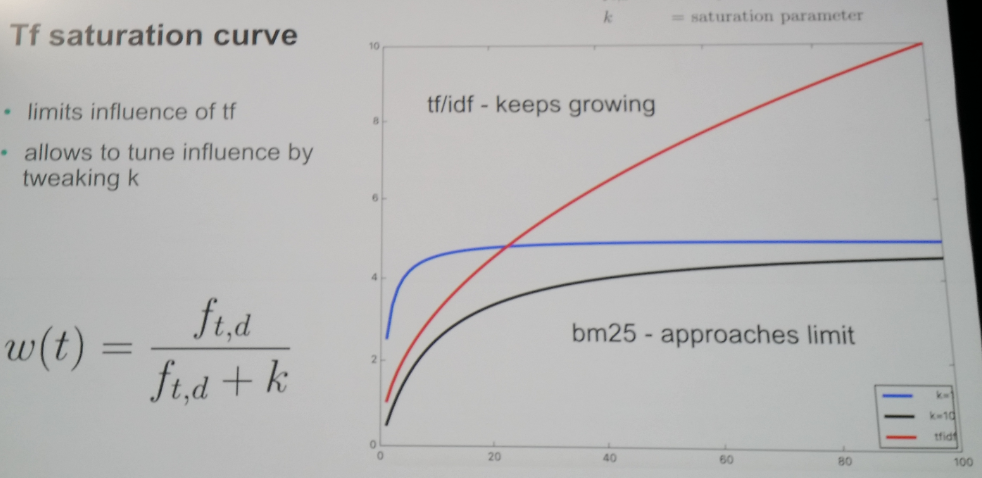
What this really means is that the term frequency will have cutoff and having more terms will not affect where TF/IDF keeped growing. BM25 also won’t automatically boost short fields. If you want to boost short fields you need to do by yourself.
New features in Kibana
Export
It is now easier to create Kibana templates when you need to use same kind of functionality in several projects because you can now export/import stuff in Kibana.
Status page
Ever been interested about how Kibana is doing? Now you can with status page!
Plugins
Here are three plugins I found to be interesting ones: Watcher, Timelion and Graph API.
Watcher is a plugin that can be used to get alerts from Anomalies in your data. You should read more from here
Timelion is all about timeseries. If you are interested about it more go check it out at elastic blog
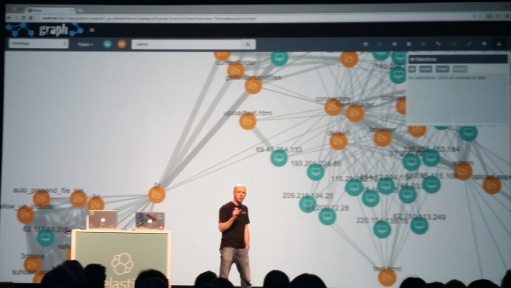
Another interesting plugin is Graph. It is not released yet but we expect it will be available soon. It is about visualization of relevancy of documents in relational diagrams.
ElasticSearch and Windows
There is now Azure template for ElasticSearch available in Azure Marketplace. You can install a cluster with master, data and client nodes with it. Kibana can also be installed with the same template. ElasticSearch is also working on getting MSI installer package ready for Windows to help Windows installations. NEST (the .NET client library) has been under heavy refactoring and will be also getting version 5 among other products upon release.
Few interesting business use cases from Elasticon
New York times
New York times has been there since 1851 publishing articles and they use Elasticsearch for full-text search among all of those articles. They have several sources for information:
- CMS
- Legacy systems
- File based archives
- OCR
Keeping latency low is very important for them for their customers to keeping up in the website. They also listed typical use cases for their own customers that are following:
- Find something you read (on paper)
- Find something you wrote
- Find reviews for books or movies
- Find recipes
- Manual sharing (somebody told to look for something like this)
- Casual news search
- Serious research
Some people have been asking why not just customer to use Google? Well there were few reasons for that. They did want to control that their customers are kept in their site. There is no Google for native apps. New York times also think that they know their content better than Google and they feel they can do better than Google in finding stuff from their site.
Hotel tonight
Hotel tonight is a company that provides a way to book hotel spontaneously for tonight. To give the best alternetives they need to find suitable hotels by geolocation, find all the rates for each hotel and rank them somehow for the customer. To achieve this they are using Elasticsearch.
Activision
Activision works in gaming industry. They shared stories about two different use cases for Elasticsearch in their industry.
Gamers are talking about Activision games in Twitter. Activision uses Elastic stack to keep up what is happening in Twitter. By having this they can for example notice when people are complaining about the game a lot in the twitter which might be cause by for example poor server performance. They can this way harness the information in Twitter to be part of their monitoring infrastructure in top of their internal monitoring systems. They also provided an example how to use Elasticsearch from Clojure.
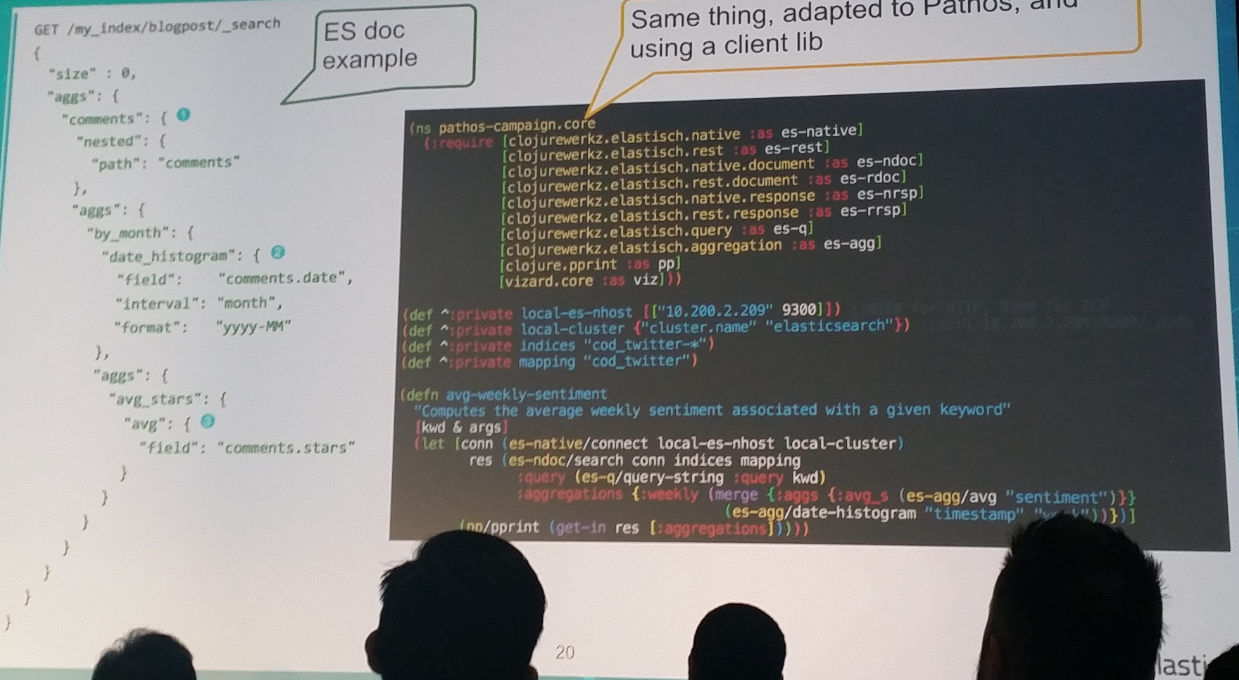
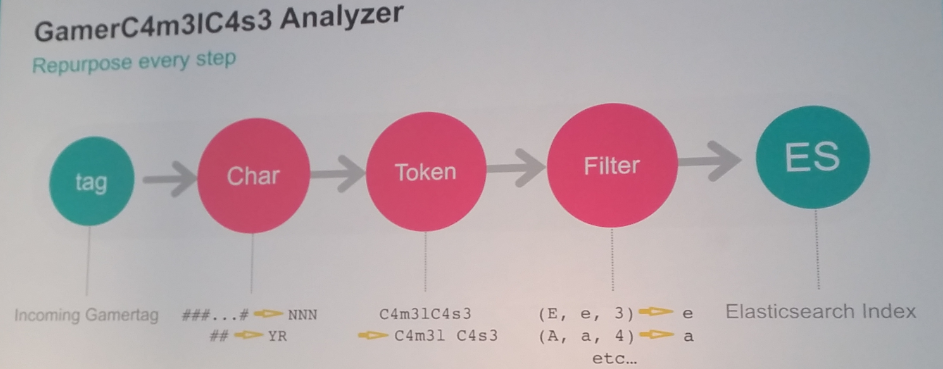
Activision has need for finding information about player based on their gamertag. So they created a gamertag-findernator. This could be used for example by their service desk when somebody gets upset about how some other player talked about his mum. The problem with the gamertags is that there are a lot of them.

And it might be difficult to find the correct “count zero” among these ones:

So they build up an analyzer pipeline that sanitizes the gamertags for search and provides also exact information about the original tag.
Goldman Sachs
Goldman Sachs is one of the biggest users of Elasticsearch. They have been using Elasticsearch since 2012 and they have had over 700 nodes of Elasticsearch in use at late 2014. This time they shared a use case of trade tracking. Highly simplified trade tracking workflow is something like the following:
- Enter order
- Book trade
- Match trade
- Allocate trade
- Confirm trade
- Settle trade
- Resolve trade
They wanted to analyze the inefficiencies and hot spots to be able to enable continuous improvement on the subject. Trade are flowing across distributed system architecture that is spanning over organizational, functional and technical boundaries. From supportive perspective they want to know where trade messages are right now, what is expected time for messages to flow and are there messages that requires attention. From analytics perspective they want to know if something is slower than usual, did their changes affect the delivery time and where to invest to optimize the flow.
They are now having 6 billion docs in 22 Elasticsearch nodes (4core, 32G RAM, 2TB). Daily volume is 45 million docs.