A group of six people went to EuroClojure 2015 from Solita at the end of June. All of our offices (Tampere, Helsinki and Oulu) were represented so that we could spread the word throughout Solita more efficiently after we came back. Also this was a superb opportunity to get to know guys from other offices better too. It was a very busy two days at the conference with many interesting talks.
 The guys from Solita who went to EuroClojure 2015
The guys from Solita who went to EuroClojure 2015
Here is a brief look at the presentations given at the conference.
Day 1
Clojure, a Sweetspot for Analytics
The first day started by registering into the conference at 8 am. After drinking some coffee and refreshments the show started with a presentation about using Clojure with analytics work. Alex Petrov from ClojureWerkz gave the talk and he mentioned that although other languages (mainly R and Python) have pretty much dominated the analytics world Clojure has been growing steadily and for a good reason.
Alex mentioned that this was his first time giving a conference speech and unfortunately it showed. He spent way too much time going over irrelevant subjects and in the end he had to skip over half of his slides since he ran out of time. Because of that the talk was a stub and it was pretty hard to grasp the bigger picture or message Alex was trying to tell us. However, he did mention two different tools for analytics on Clojure, Anglican and Statistiker. Anglican is actually a new language for analytics work built on top of Clojure. It’s a macro heavy implementation and provides straightforward declarative approach to analytics with Clojure. Anglican did seem somewhat interesting and worth keeping in mind in case you end up doing analytics work with Clojure. The second library, Statistiker, is a ClojureWerkz project which is heavily in development. Apparently Alex was involved in development of Statistiker but it’s maturity is a big question mark for now. It might be worth a look later though.
What lies beneath - A deep dive into Clojure’s Data Structures
Next Mohit Thatte from India gave a talk about Clojure’s data structures and how they work under the hood. Mohit was a good speaker and he managed to keep his presentation both interesting and funny at the same time. The first half of the presentation felt bit too much like university lectures about data structures: stuff like how trie or red-black trees work was explained and so forth.
 Challenge accepted!
Challenge accepted!
After the first half though the presentation got more interesting when Mohit dug into the more modern datastructure implementations which are also in Clojure itself. There’s a suprising amount of little tricks and optimizations going underneath the hood to give us the fast persistent data structures we have in Clojure. Tip: binary operations are the king :) A nice fact was also that Clojure’s persistent implementation of HAMT trees are also the first in world anywhere. So Rich Hickey got himself to datastructure history with his work and that implementation has been copied to several other languages later on. Overall this presentation was quite nice and entertaining although it didn’t really give anything tangible to help us in our daily work.
Building a real world, end user, open source application in Clojure
Guys from Bevuta IT came to talk about project they had been working on with full-stack Clojure. Moritz Heidkamp and Moritz Ulrich (the Moritz brothers?) first showed us few slides about their application PEPA, which was a pretty basic document management system. Slides contained few bullet points and few screenshots and from there it was a deep dive into Clojure code written into their system.
PEPA seemed to follow a pretty typical good architecture for a full-stack Clojure project. They used Stuart Sierra’s Component, Om and so forth. The whole talk could be described as a ‘code review’. Although it was pretty interesting the most you’ll get out of it is to just go and read PEPA source codes from Github. PEPA looked like a well made piece of software and it could be used as a loose reference point for your own full-stack Clojure projects.
Mesomatic: The cluster is a library
After the break Pierre-Yves Ritschard talked about Mesomatic which is a Clojure library for working with Apache Mesos. Pierre-Yves spent a lot of time in the beginning going through how application scaling demands grow when it gets more popular and he tried to build a foundation for his talks main point with it. Unfortunately in my opinion he spent way too much with that part of the talk and I was just about to doze off when he finally go to the point which was Mesomatic and Mesos.
For those of you who don’t know Mesos, it’s a library to control your applications in a cluster in such a way that you won’t be deciding where your applications are running. You just define resources your application needs and throw it at Mesos which will decide where to put your application and runs it. An important part of Mesos is also message passing mechanism between these applications. Mesos provides a very dynamic way to scale your system across cloud environments where servers can come and go and only those applications are ran which are needed at that specific time.
Mesomatic was nothing more than a Clojure library to control Mesos. Mesos is most definitely a very interesting abstraction over operating systems and could provide a very nice way to handle your cluster if you have a big enough system to gain the benefits of Mesos.
Where’s my data?
David Chelimsky from Cognitec gave a presentation about Datomic. In case you didn’t already know, Datomic is an immutable temporal database which is pretty much the coolest database out there. I’m pretty sure that most of the audience already knew what Datomic is though so this presentation wasn’t really needed that much. David was an excellent speaker and he did give us some first looks at the new stuff coming at Datomic (pull API is really nice and it composes with query API seamlessly) so I didn’t feel like my time was wasted. However I would have liked to see something which isn’t already known by the whole Clojure community instead of this presentation.
 Datomic data traversal
Datomic data traversal
Generative Testing: Properties, State and Beyond
Generative testing is a testing method first defined by John Hughes when he was working at Ericsson. Jan Stepien gave a presentation about generative testing with Clojure with test.check. The main idea of generative testing is that you don’t write tests with fixed input values but you write generators which will generate (possibly) an infinite amount of variations for the input parameters. You define properties for your tests and let test.check execute your test hundreds or thousands of times. This allows one to find hidden bugs and makes it possible to write reliable tests for eg. concurrent scenarios.
John Hughes thinks that you shouldn’t write any other tests than generative tests. They are definitely a useful testing method especially when you test pure functions - although one can test impure functions as well, they just need more scaffolding to get running (but that’s true also with unit and integration tests).
Overall this presentation didn’t really give me anything new but what it did do was that it reminded me of the existence of generative tests. I actually already took test.check into use in our project when testing some parser logic.
Beyond Code - Repository mining with Clojure
Next presentation was the best of the first day at EuroClojure. It was a suprise since I didn’t really expect anything from the presentation name and abstract.
Adam Tornhill talked how when trying to improve the quality of large systems the most important part isn’t actually the code itself but version history. This was a really interesting proposition and Adam managed to convince at least me that he is most likely correct in this matter.
During the presentation Adam went through several cases where just by analyzing version history log data one could find:
- Worst code in the system which contained most of the bugs
- Code with dependency problems
- Code with logical problems
- Copy-paste code
- and many other things
This was done mostly via analyzing temporal coupling of different commits and changes to different files. For example, if two files are changed at the same time they almost always contain some kind of coupling between them. It can be a logical coupling which could mean they actually should be in one file. Or it can be because they contain copy-paste code and when you change the first file you also need to do the same changes to the second file too. And stuff like this.
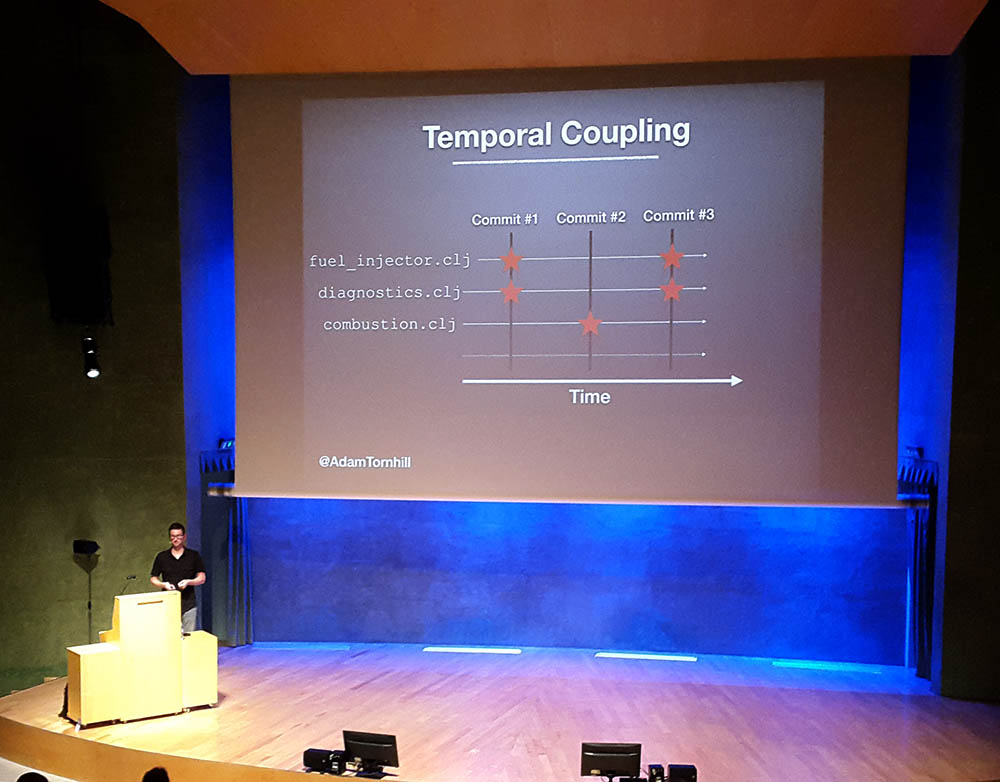 Temporal coupling in version history commits
Temporal coupling in version history commits
Adam has written a tool with Clojure called code-maat which is a command line tool for doing temporal analysis from version control data. The tool is language agnostic and can read log data from Git, Mercurial, SVN and Perforce. He also has written a whole book about this concept called Your Code as a Crime Scene.
This talk was inspirational and will most likely lead to at least something at Solita. Definitely recommend to spend your time on watching the video when it comes available.
Clojure on Android
Alexander Yakushev is a the guy responsible for Clojure Android which he started few years back when doing a Google Summer of Code project on it. Today one can develop full blown applications for Android with Clojure and Alexander gave us the very first live coding session in the conference. When doing that, Alexander built a very simple Android application with full REPL support and everything directly from Emacs.
Today Clojure Android consist of several projects which give you all kinds of tooling, libraries and more. One of the most interesting parts of Clojure Android from web developer perspective is Skummet which is a Clojure optimizer. What Skummet does is that it removes all dynamic bindings from Clojure bytecode which improve bootstrapping time significantly (over four times faster!). After dynamic bindings have been removed this opens doors for other optimizations too such as tree shaking via Proguard since the functions are just static methods after the var removal. This both improves performance and lowers the footprint of application binaries. The best part of all this is that Skummet is not limited to only Clojure on Android but it can be applied to any Clojure application. You’ll lose dynamic var functionalities and eval but most application don’t need those anyway when in production.
I was hugely impressed on work done on Clojure Android and it seemed to be suprisingly mature platform to build applications on.
μKanren: Running the Little Things Backwards
First day was concluded by the functional programming world’s very own superstar girl Bodil Stokke. Bodil had apparently noticed that there was quite a many finns in the conference since she started her presentation by saying “Hyvää iltaa” which is “Good evening” in Finnish. :)
Bodil did a very typical presentation for her with first few slides with horrid colors and comic sans font and then diving deep into live coding with Emacs. Bodil implemented a micro sized logic language with Clojure live on stage during her presentation. I have to say I had very hard time keeping up with her and felt myself incredibly stupid. For my relief she concluded her presentation by saying that she just went through several decades of computer science research work in 45 minutes. That made me feel a bit less stupid :)
However it is truly impressive what you can do with just a tad over 100 lines of Clojure code. μKanren isn’t something Bodil implemented but it is something she truly grasps intimately. Bodil is an inspirational figure all with her Nyan Cat decorated Emacs frenzy and all programmers should see her giving a presentation at least once in their lifetime.
Conference party
After the first day of presentations there was a conference party in a local night club which lasted until midnight. There isn’t very much to say about the party except there was free beer (for a limited time) paid by Cognitec and an awesome chance to network with other Clojurians. Had a nice time although after the free drinks seized to flow the prices went through the roof: 7€ for warm Budweiser and 12€ for gintonic. Maybe this was a scheme to prevent the conference visitors from getting too drunk so they’d manage to get to the second day in time since the first presentation was already at 8:50 AM. This scheme failed miserably though since last message into EuroClojure Slack channel had been written at 4:30 AM.
Second day
Ctries in Clojure, or Concurrent Transients
Second day was launched by a presentation by a very intelligent man called Michał Marczyk. He talked about a datastructure called ctries which he had implemented for Clojure as a library. I’d love to tell you all the nasty details how this datastructure works but I have to admit I just couldn’t follow this presentation. While Michał is obviously a very intelligent man he unfortunately lacks basic presentation skills. He failed to explain many concepts which he took for granted and jumped back and forth between his slides which didn’t really contain any detailed information about how the datastructure worked. Ctries is a very nice datastructure and it’s great we have it on Clojure but you’ll understand better how it works by watching a presentation by Martin Odersky about it.
Talks starting at 8:50? Brutal. First talk is by Michał? Fatality. #euroclojure
— Andrii Mishkovskyi (@mishok13) June 26, 2015There was this godlike tweet written when this presentation was going on. One can only understand this tweet if you have sat at the conference at 8:50 AM after spending quite a lot of time and alcohol on previous night. Super heavy duty stuff as the first presentation.
Grudging Monkeys and Microservices
Second presentation was a lot easier on your mind and was perfect for waking up people after the party night. Carlo Sciolla gave a presentation about how one should (or could) build infrastructure for true microservice architecture based application. He used this super simple example application as an example which consisted of applications called Monkeys. Each Monkey behaved slightly differently and they effectively implemented a single microservice each. On top of these was a simulator which talked to these microservices and provided a web based UI for the application. The application didn’t do anything truly interesting but it was enough to demonstrate a microservice application in action.
The true beef of the presentation was the tooling and how they were tied together. Carlo bombarded us with whole slew of tools:
- Consul.io
- Go Continuous Delivery
- Terraform
- Hysterix
- ELK stack
- Elastic Search
- Logstash
- Kibana
- New Relic
- Mesos
- Docker
- and several others
Carlo emphasized that you need to pay dearly to get microservices truly running but if you do, the benefits are great. I personally loved his approach of not concentrating on the application itself but on how to best implement a very robust microservices architecture infrastructure. This talk gave me good tips on several new tools I didn’t know of and made me think about microservice architecture in overall. Good talk.
Efficient & Concise Access to Remote Data - Reinventing Haxl
Alexey Kachayev gave this presentation (which had slightly changed it’s name from the schedule on EuroClojure webpage) which was a true suprise. Alexey gave one of the best talks of the whole conference and his library might be a really big thing in Clojure world in the next few years.
Muse is a library which is heavily influenced by Haxl and Stitch which are developed by Facebook and Twitter for Haskell and Scala. What it does is that it provides a declarative way to describe data sources and concurrent communication between those sources. Muse makes the requests and is smart enough to not do the same request twice when doing it’s work so the developer doesn’t have to worry about performance problems caused by such things. It also automatically parallelizes these requests if possible and then does logical merging from these sources as defined by the developer.
I had heard of Haxl before but hadn’t really dug into what it truly is. This concept is truly interesting especially in the microservice world since it simplifies significantly the overhead of communication logic code between the services. Muse is a very impressive and beautifully written piece of code and it does it’s magic with only 254 lines of Clojure code.
Real Estate Clojure
Next talk was a project case story about building onthemarket.com which is a real estate marketplace in UK. Jon Pither gave an entertaining talk how they approached the problem and what problems they faced during the development. There isn’t that much to say about this talk except Clojure saved the day and in the end they delivered a performant and beautiful (I agree) website which does it’s job well. As a nice sidenote Jon praised compojure-api by Metosin like nothing else. I guess @ikitommi smiled pretty widely during this talk :)
ClojureBridge - Building a more diverse Clojure community
Ali King came to tell the Clojure community about ClojureBridge - a movement which tries to get more people from the minority groups into Clojure programming. With minority groups Ali meant women, disabled people and so forth. While I understand how diversifying the programmer pool in Clojure world will be a good thing I didn’t really enjoy this talk. While Ali did speak clearly she also gave her talk by reading it from notes. This made the pace of the talk unnatural and mechanic and thus hard to follow.
The subject of this presentation was a bit dangerous and it almost blew when it came time to make questions. There were several plain stupid questions and one which could be considered as rude to the speaker. What these questions proved to me though that ClojureBridge is indeed needed since obviously there are still people from stoneage even in the Clojure community. After the presentation at least one new ClojureBridge event was created so mission accomplished Ali!
Performance and Lies
After the lunch break it was time for Tom Crayford to step on the stage. During the lunch we talked that the next presentation could only be either super bad or super interesting based on the topic. Fortunately what Tom gave us was of the latter type.
Not only did Tom manage to make his presentation entertaining and fun it was also packed with interesting information about how JVM and Clojure works. There’s over 800 different flags which you can give to JVM but Tom brought up few of those which are truly interesting for performance tuning:
- -Xmn -Xmx, which is the basic heap tuning arguments. Tom said you can gain 15% performance boost just by tweaking these according to your application.
- AggressiveOpts. 8.4% performance boost.
- UserCompressedOops, which will propably win the “best name for a flag” competition and also can give you a 8.1% performance boost if you turn it off.
As an interesting additional information Leiningen runs by default with -XX:TieredStopAtLevel=1 which tells the JVM to optimize startup time, not runtime performance. As a result one should turn this off if you want to do any kind of benchmarking via Leiningen. Did not know this.
Also one can gain quite significant performance improvements especially with Clojure by tweaking MaxInlineLevel=9 to something different. What this flag does is that it limits the JIT on how many function calls it can recurse into when doing inlining. Since Clojure is a functional language and it does a lot of function calls this can make a huge difference with certain applications.
Tom also made a thrust at profiler builders and told that all of the profilers on JVM lie. They cannot do anything else since they effectively work on JVM safepoints which allow debuggers, profilers etc to tap into the normal execution of your application. During a safepoint your application doesn’t proceed at all and the tooling can do their magic. The reason for profilers lying is that these safepoints do not happen at even intervals during the execution and thus profilers might miss important information between safepoints. That doesn’t mean that profilers wouldn’t be useful tools, it just means you shouldn’t rely too much on them.
There was a ton of other stuff too on Tom’s presentation and I suggest you’ll check the presentation video out when it comes online.
Realtime Collaboration with Clojure
Leonardo Borgas from Atlassian came to talk about product he’s been working on. It’s a collaborative wiki platform similar to Google Docs. The main problem with applications as these is the conflict possibility between concurrent edits and how to handle these.
Leonardo gave a pretty thorough analysis of the problem and its possible solutions. In the end he told that actor model is a perfect match to solve this problem but on Clojure there is a problem: we do have several actor model implementations for JVM (Akka, Pulsar) but none of these work on top of ClojureScript. And Leonardo’s team wanted the actor model to be preserved throught the application chain to gain the best benefits without resorting to ugly hacks.
Because of this they had written their own mechanism on top of core.async which was somewhat similar (but not quite the same) as actor model. At this point I was starting to get really interested but then Leonardo told us that it is still a work in progress and not ready. Apparently they are planning to opensource the implementation when it is finished which is interesting.
This presentation left me with mixed feelings. On the other hand the content was interesting and the proposition of this new actor(ish) library was equally so. But I would have loved to see some demos of this whole collaboration platform in action or example code of how to use their library. It seems like EuroClojure came too soon and this presentation would have been a lot better half a year from now.
Om Next
The very final presentation and unofficial keynote was given by ClojureScript God Almighty, David Nolen. The topic of the presentation was a bit misleading since only half of the presentation was about Om Next and the rest was about ClojureScript’s future.
Om Next is coming and it’ll totally change what Om is. It is backwards incompatible and effectively a completely new UI library on top of React. The biggest change with Om Next is going to be removal of cursors. Like Nolen said: “cursors gave us 16 months of time to figure out how to do this properly”. The answer is the pull API which is identical to Datomic new pull API. It allows the developer to describe in this specific query language of what data the component is interested in and Om Next takes care of providing you with that data.
The second huge change is the fact that Om Next is moving forward from using REST APIs to different way of doing things. With Om Next you won’t force your server side APIs to grow into huge monsters which are very hard to maintain but it’ll encourage you to create query APIs on your server side and use those from client. Without going to too much into details you can think of this a bit like creating datalog queries from your client directly to the server. This allows keeping the server side API lean and allow client code to make the business decisions about data.
 REST APIs as seen by David Nolen :)
REST APIs as seen by David Nolen :)
I personally think this is the way to go and I’ve actually implemented similar system in my history. It was super nice to use, although definetly nothing as elegant as the one in Om Next. One has to think about security concerns and so forth a bit differently in an approach like this but it’s all quite doable.
The second part of Nolen’s presentation was about ClojureScript and its future. First of all, ClojureScript is not thought to be only for the web but for all platforms where JavaScript can run. Due to this vision there has been quite a lot of work on tools to make it all happen.
Work on ClojureScript to ClojureScript compiler has started and a simple version of it is already working. It still needs macro support and whatnot but still it’s looking nice already. No word on when it would get ready though.
There is a Google Summer Code -project going on which is concentrating on conversion tool for other JavaScript module systems than Google Closure. If this is successful, it’ll be a huge thing for ClojureScript ecosystem since the amount of usable libraries would grow exponentially. Nolen mentioned that work has been done on converting CommonJS, AMD and EcmaScript 2015 modules.
Last part was a demo of Ambly, which is a development tooling for iOS development with ClojureScript. Nolen changed OpenGL ES -application running on iOS emulator on fly by using ClojureScript REPL. Which was pretty awesome, full REPL support for iOS development? Who wouldn’t want to get that?
Conclusion
Overall the quality of the presentations at EuroClojure 2015 was above average of the conferences I’ve visited in. There were better and worse presentation like always but there definitely were thought provoking presentations which will affect our Clojure development at Solita in some way in the long run. Let’s try to take over the world with Clojure!
 It’s time to take over the world with Clojure!
It’s time to take over the world with Clojure!
Jarno Väyrynen also wrote about our trip into Solita’s finnish blog, you can read about it from here.