This article shows how we created a simple deployment pipeline using open source components. Obviously you must first do Continuous Integration (CI) to enable DevOps and Continuous Delivery, but then what? How to move from plain CI arrangement to Continous Delivery? Here’s one answer.
The first rule of DevOps is you don’t talk about ‘DevOps’
It is good to remember that DevOps is about culture, not tools. I dislike the notion that “DevOps brings together two kinds of people, Developers and Operators”. It’s a start, but as a project manager I have little use for a “developer” unwilling to learn linux administration, and even less use for an “operator” uncapable of writing clean code.
We are not Twitter. Neither are you.
Some of the “best practice” references come from famous product shops, such as Twitter, Etsy, Google and Facebook. Their context is very different from an average enterprise project team’s context. Most of the software teams are not running hundreds of servers with dozens of applications. Our context is basically handling a couple applications, one team and perhaps a dozen servers or so. Still, I prefer that installations are automated and servers do not break arbitrarily because of human errors.
Shipping is a feature!
As Joel Spolsky succintly put it, Shipping is indeed a important feature. Let’s separate the concerns of this fundamental feature. The basic problems are:
- how to use version control to manage changes in the source code (branching model/process)
- building the package (compilation and dependency management)
- tagging the installation package with a version number
- storing and distributing the installation packages
- running automated test suites
- configuring the environment
- deploying the software
- monitoring
There are a number of companies and products who promise to take care of most or all of these problems. Easy and quick is a tempting proposal, but is it a enabling platform or a framework solution? What happens if you need to go beyond the planned roadmap? With frameworks, Pain happens.
You shouldn’t take for granted anything said about the “optimal” tool or solution. The context of the project defines what is appropriate and valuable.
Jenkins is a hammer
Our solution provides automated configuration management, automated deployments and build promotion. Our only special “DevOps tool” is currently Ansible. Jenkins is our hammer.
- Jenkins is used as a nice
cronUI and dependency orchestrator. It glues together the steps of the deployment pipeline, but doesn’t really know that it’s even building a software package or doing any deployment. We use freestyle projects and shell commands instead of Jenkins “Maven projects”. Build pipeline plugin allows visualization of the pipeline and the dependency graph shows the trigger paths.
Here’s how our delivery pipeline looks like in Jenkins.
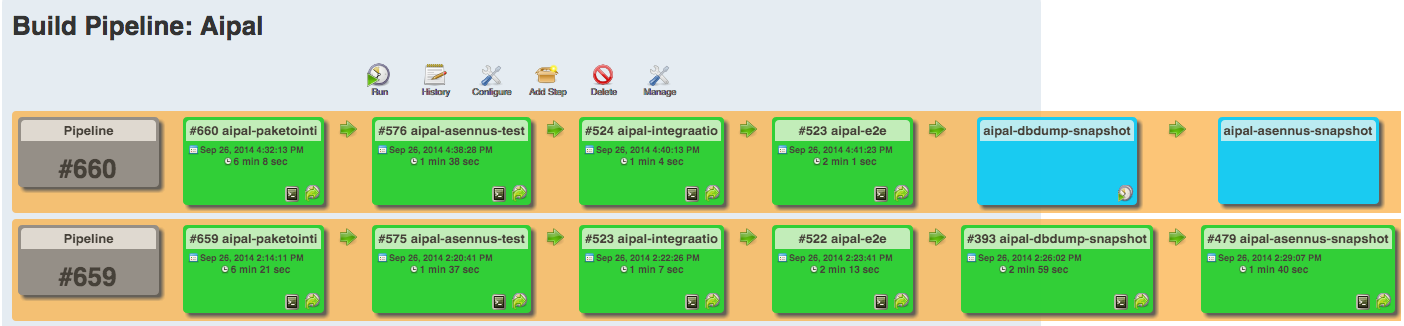
- As suggested in Continuous Delivery, page 43 we have separate git repositories for appplication source code, data and server configurations. Our source code is public, but our data is not. Checkouts from multiple repositories didn’t work properly without the Multiple SCMs plugin.
Build promotion
This is the first step of our pipeline. Jenkins doesn’t know it, but the script creates version numbers for our binaries to enable proper build promotion.
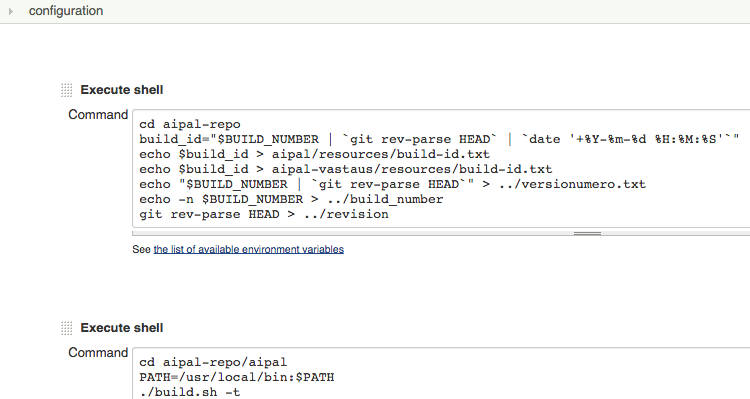
Our version numbers are not Maven component versions, but Git hashes combined with a build id. This works because Jenkins also hosts the packages. This solution is not ideal for all projects but avoids burdens of a separate component repository. See our post about Jenkins build pipelines for more information regarding Jenkins build pipelines and the limitations of this approach.
After packaging
-
Jenkins runs automated test suites. For fast failure the test suites are separated to multiple Jenkins jobs which run in a sequence.
-
Environment configuration is handled with Ansible. Jenkins polls our git repository and asks Ansible to do things. Cloud provisioning happens with a few shell commands.
-
Ansible deploys the packaged software. Jenkins calls Ansible whenever necessary, but Ansible handles the actual deployment process. Only packages which have passed the test suites can be deployed.
Poor man’s monitoring
Simple monitoring can be arranged with Jenkins, wget and Ansible. This is not suitable for “real work” but there’s New Relic and others for more complex monitoring. Running uptime through Ansible to all hosts is far easier than setting up Nagios to provide the same information.
To see that our demo environment is responding we use this simple script triggered with Jenkins cron. If the ping fails, Jenkins sends an email to the team and the ping job turns red on our information radiator.
#!/bin/bash
if wget -q --user=xx --password=yy "http://1.2.3.4/demo/" > /dev/null; then
echo "ok"
exit 0
fi
echo "FAILED"
exit 1
Simple radiator setup
Our information radiator shows the status of CI builds, nightly automated deploys and the ping status.
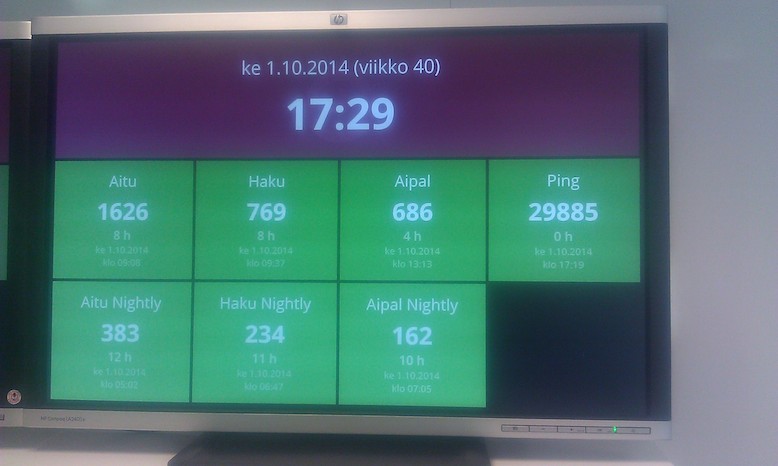
This iteration of the radiator was built with Dashing, but you can get quite far with 50 lines of Javascript without any special libraries. Our radiator runs a simple loop in a web browser:
- Fetch some JSON/HTML from Jenkins.
- Display it in some simplified format.
- Wait a minute or so and start again.
I want a cordless screwdriver
Jenkins is our hammer and shell scripts are nails, but I don’t actually want a hammer.

(Picture from the mighty and most awesome FAKEGRIMLOCK)
I do not know how our pipeline evolves, but we currently use a small subset of Jenkins features. Used in this manner, Jenkins has become our enabling platform for continuous delivery. It wasn’t designed to be that and I believe a better replacement will soon emerge. The replacement should have these qualities:
- better implementation of security and access control.
- pipeline view, multi SCM, parallel jobs available as default.
- jobs and configuration as code. Jenkins stores them in XML files. This makes automated configuration and provisioning of Jenkins difficult.
- support for build promotion.
- plugins/API for provisioning with Ansible or other tools.
- better support for radiators. Provide sane templates for radiators out-of-the box.
- installable. SaaS clouds (CircleCI and others) are great for some teams, but for us this requirement is absolute.
- Designed to be an enabling platform, not do-it-all solution with fixed workflows.
Getting things done
The strength of this solution is that there is nothing really complicated about it. One doesn’t need special tools and skills to maintain it. Understanding basic linux administration does not count as a special skill in my opinion. Jenkins server is required for Continuous Integration anyway and we simply leveraged it to do Continuous Delivery and monitoring as well. Even Ansible isn’t actually required - we used plain shell scripts in the beginning.
There are other projects in Solita with zero downtime deployments, SMS alarms and other Etsy-style blingbling practices, but they operate in a different context. The bells and whistles have a price tag - more tools, more complexity, more maintenance work. Seek the sweet spot which maximizes the value in your context and go there.